Now, let’s go back to our pitfalls and also talk about a “war” that’s being going on for the past 40 years: the Editor war. It might sound like a silly war, or a simple matter of preferences, but trust me: it’s not just geek tribalism, it’s about fundamentally different philosophies of human-computer interaction.
I’m a NeoVim user. That means I’m one of those geeks that rather type code in the terminal istead of using something more modern like VSCode. While using NeoVim I never use my mouse or touchpad: I just type stuff and use a bunch of key combinations to navigate through the code. But I’m not alone! The first Vi editor was created in 1976 and since then its popularity has only grown between the geekiest of the software developers.
Why? Well, let’s explain that while talking about one of the pitfalls I mentioned in Munich:
Pitfall 4: The Coding Tunnel Vision
Vi and its siblings (Vim, Neovim) became popular because they allowed developers to navigate the code faster. Instead of moving your hand to your mouse, scrolling down, selecting a part of the code you want to change and then typing the change, these editors proposed a different idea: they would have modes. While on INSERT mode, everything you type on your keyboard would appear on the screen, just like it happens on any other editor. But in NORMAL mode, each key on your keyboard can be used to navigate the code.
For example: if you press 3wce you would instantly change the content of the third word in that line. (Something like: Go to the 3 rd W ord C hange until its E nd).
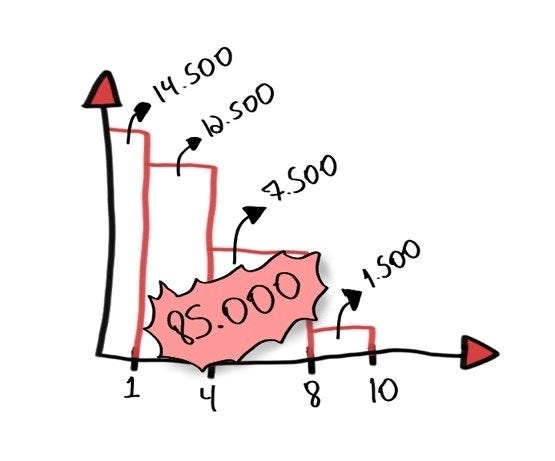
It basically creates a dialect so you can tell your editor where you want to go and what you want to do with your code without having to do it using mouse, menus, etc. And accelerating how we navigate the code is important because software developers spend more time navigating and understanding the code than writing it.
A chart representing the results of a research on how developers spend their time
So, why are we focusing on using LLM’s to generate code when we can also use it to help us understand the code? I mean, they are great coders, I’m not denying that. But in my experience they can provide much more value explaining the code instead of just creating it.
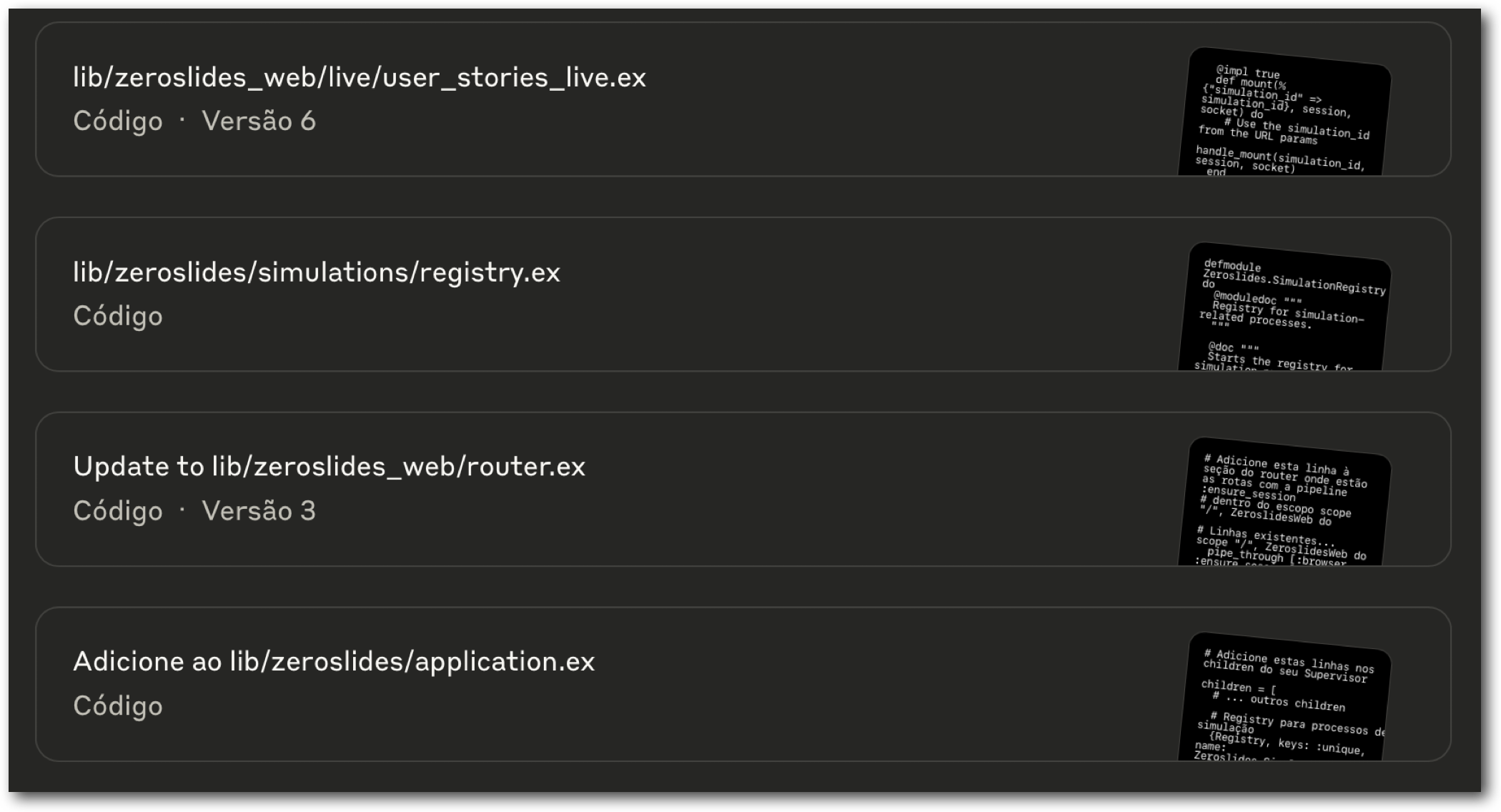
Here’s a practical example on how I did that: I’m currently writing a software to improve the practical activities I run in my classes. And at some point I decided to ask Claude to explain my own architecture to me. Because Claude excels in text output I thought it would be nice to use a tool like Mermaid, a tool that transforms text inputs into neat diagrams. I asked Claude to explain the structure using MarkDown and Mermaid, and I pasted the result on a text editor compatible with both technologies called Typora. Here’s the result:
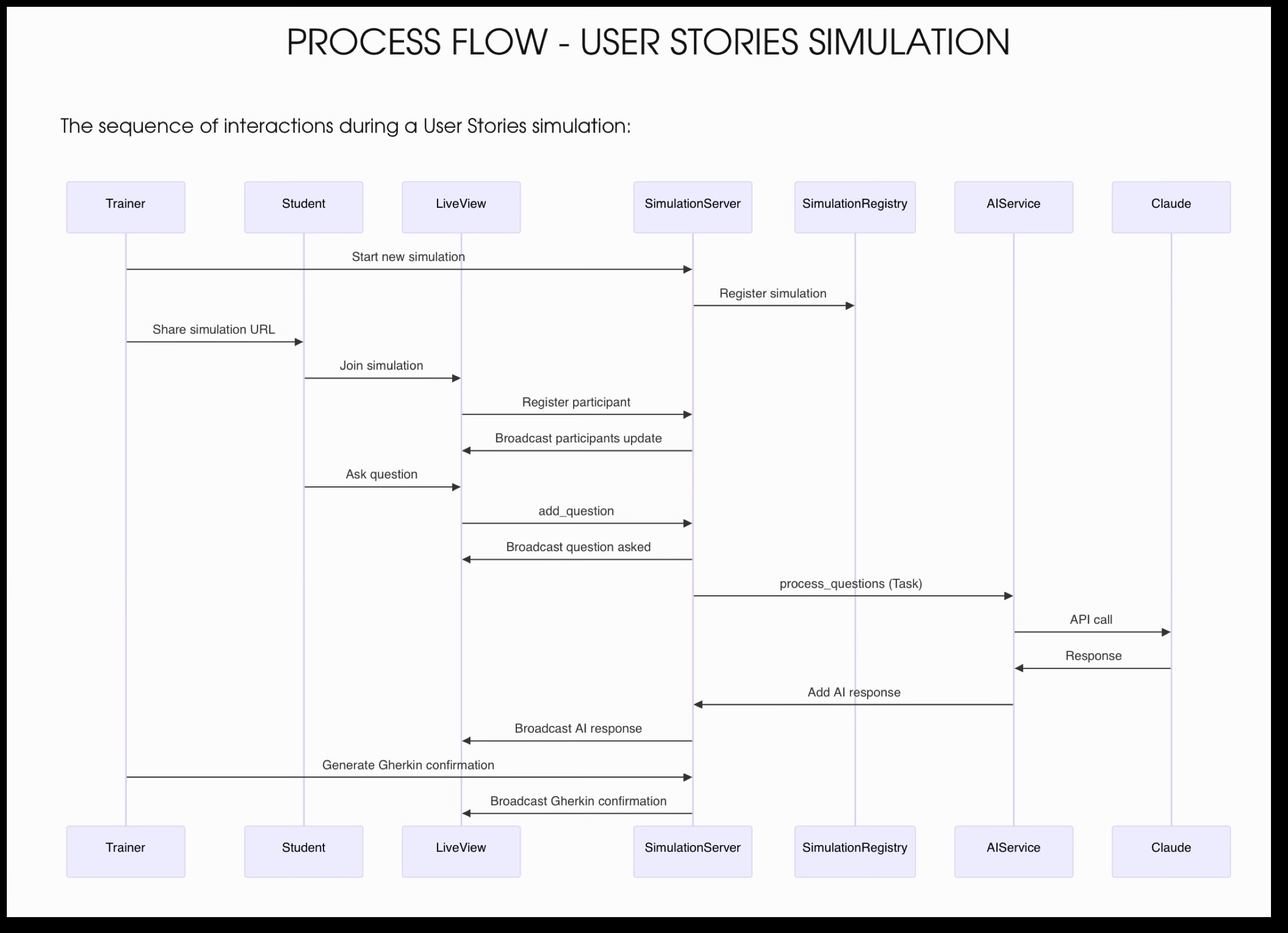
That’s a great piece of documentation that can be used to explain both the developers on my team and even the LLM itself how the architecture works! Specially because the diagram can be read by the LLM as a simple text input, minimizing the amount of tokens consumed in each interaction.
Thing is, no matter if you wrote the code manually or if an LLM wrote the entire thing for you, you’ll still be responsible to the consequences. Therefore, understanding what’s going on is fundamentally important.
Remember: if something works and you don’t know how, when it stops working you won’t know why.
Pitfall 5: The Bulk Bias
Some people are still complaining about the quality of the code generated by LLM’s and I strongly disagree with this take. In my experience, the code generated is actually pretty good.
What bothers me is the code quantity.
Specially because I don’t believe in “vibe coding” (that is: trusting the generated code and not even taking a look at it). I need to review the code and make sure it’s doing what it’s supposed to do because… I’m a responsible adult? So, when the LLM changes 8 files and adds 200 lines of code for each prompt I make, my job becomes extremely painful and well, unfun. I tried multiple approaches and different prompts to reduce this problem but I’m yet to find a solution.
To be fair Claude 4.0 presented a great improvement when it comes to this particular pitfall, and I think we’ll get a definitive solution to this one in the near future. But it’s not quite there yet.
 One prompt, MANY changes
One prompt, MANY changes
What I feel is that instead of helping us to walk faster LLM’s are helping us to take bigger steps. Both approaches can help us to cover a longer distance in the same amount of time, but the later also comes with a high cost when you’re walking on the wrong direction. The business model also contributes to it: when I use Cursor for example, I have limited tokens/interactions, which incentivizes me to take the most out of each prompt.
Conclusion
Writing about working with LLMs is a strange thing. I wholeheartedly mean everything I wrote in this post today. But things are changing fast, and this post might age like milk or wine depending on the upcoming developments. If you value learning more about this topic, I strongly suggest you to do two things: use it to create something instead of just reading about it on LinkedIn (even better: get away from LinkedIN altogether), and try to read different takes about the subject. Karen Hao’s book “The Empire of AI” might be a good start.
]]> The dark side of the vibe
The dark side of the vibe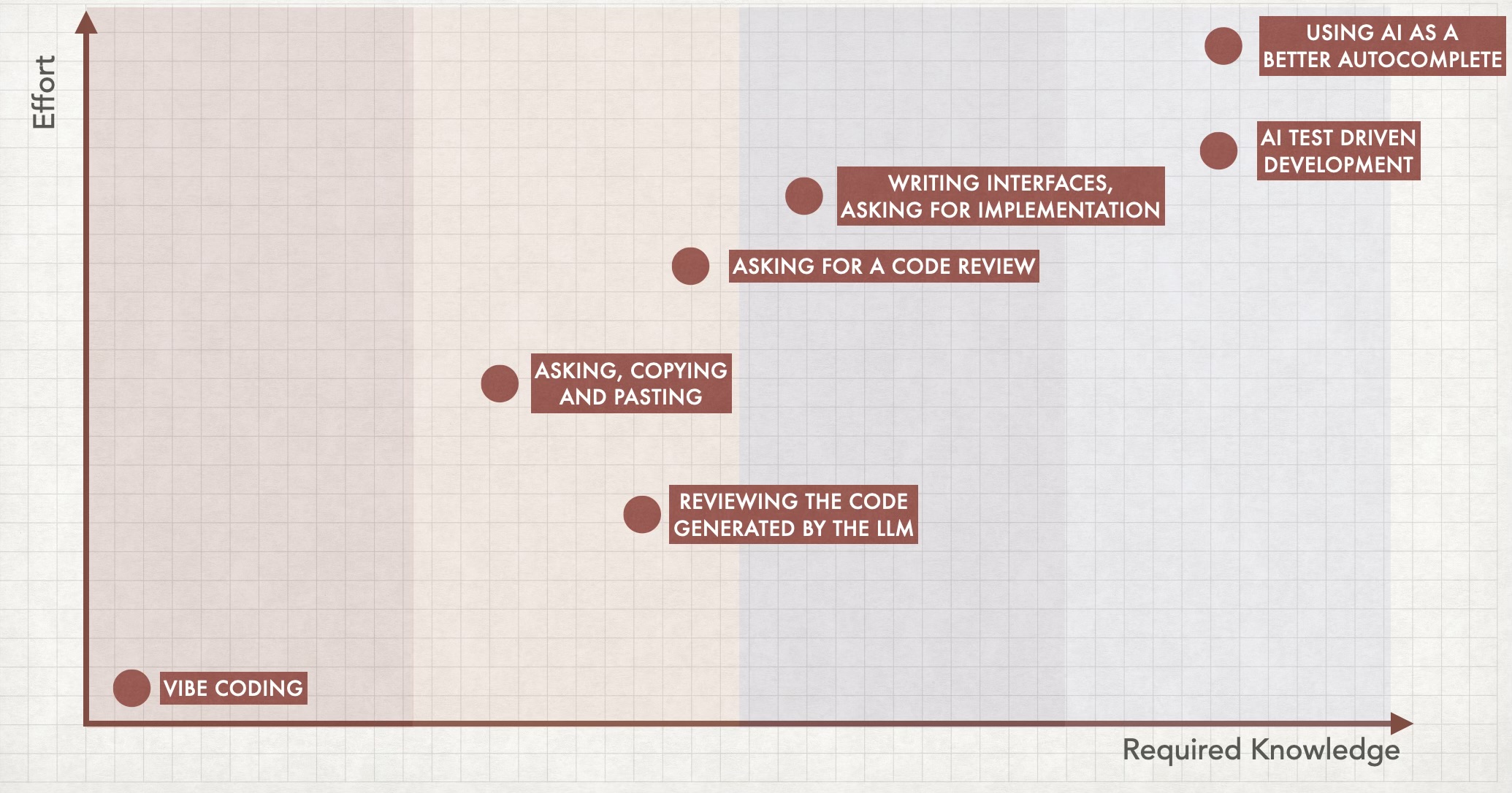 A slide from my talk: If you have more technical knowledge, you’ll have more options
A slide from my talk: If you have more technical knowledge, you’ll have more options A demo works as a “teaser” to convince people to buy the product
A demo works as a “teaser” to convince people to buy the product Hume would push the team to experiment more, and allow them to learn from their failures
Hume would push the team to experiment more, and allow them to learn from their failures

 If you never played Megaman, stop reading and go play NOW
If you never played Megaman, stop reading and go play NOW
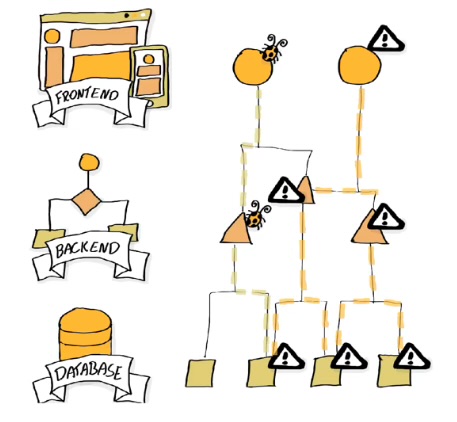
 Mobile in 2000’s: These devices could make the Nokia 3310 seem fragile
Mobile in 2000’s: These devices could make the Nokia 3310 seem fragile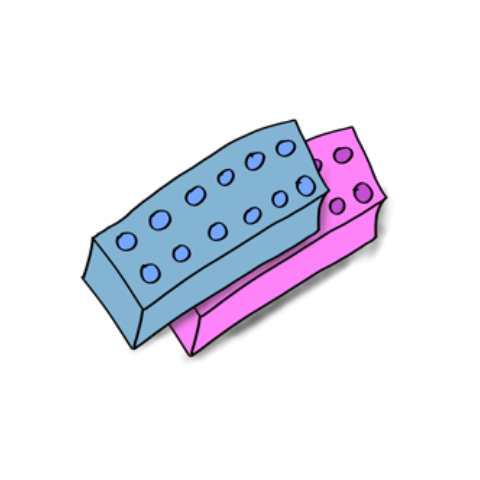 The dependency on an OTP application is a bit different.
The dependency on an OTP application is a bit different.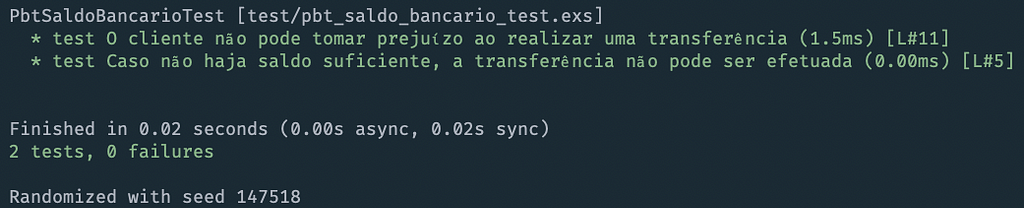
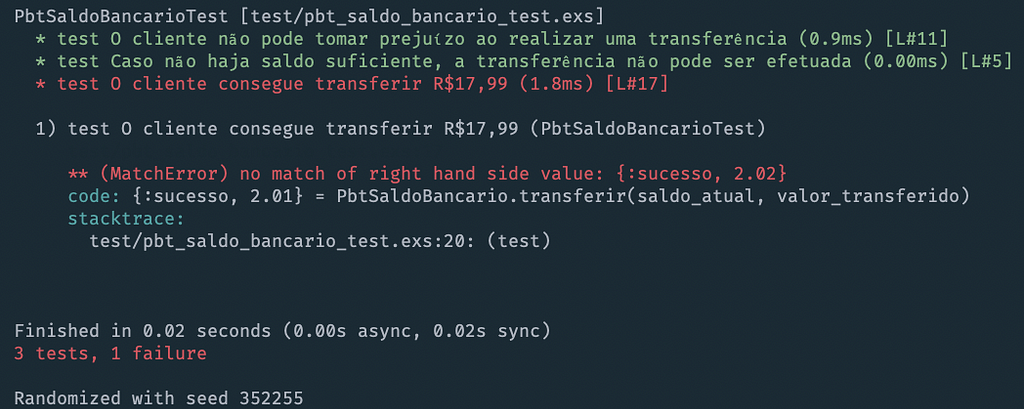 The test fails because the remaining balance was R$2.02 and not R$2.01
The test fails because the remaining balance was R$2.02 and not R$2.01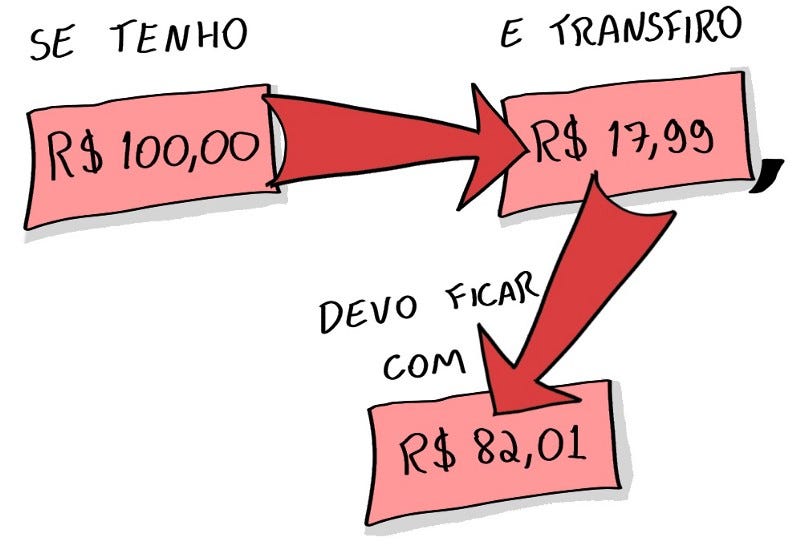
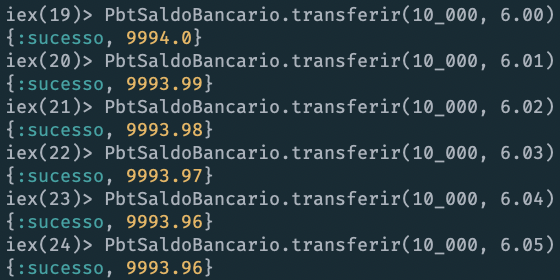 In this case, the problem appeared only when trying to transfer R$6.05
In this case, the problem appeared only when trying to transfer R$6.05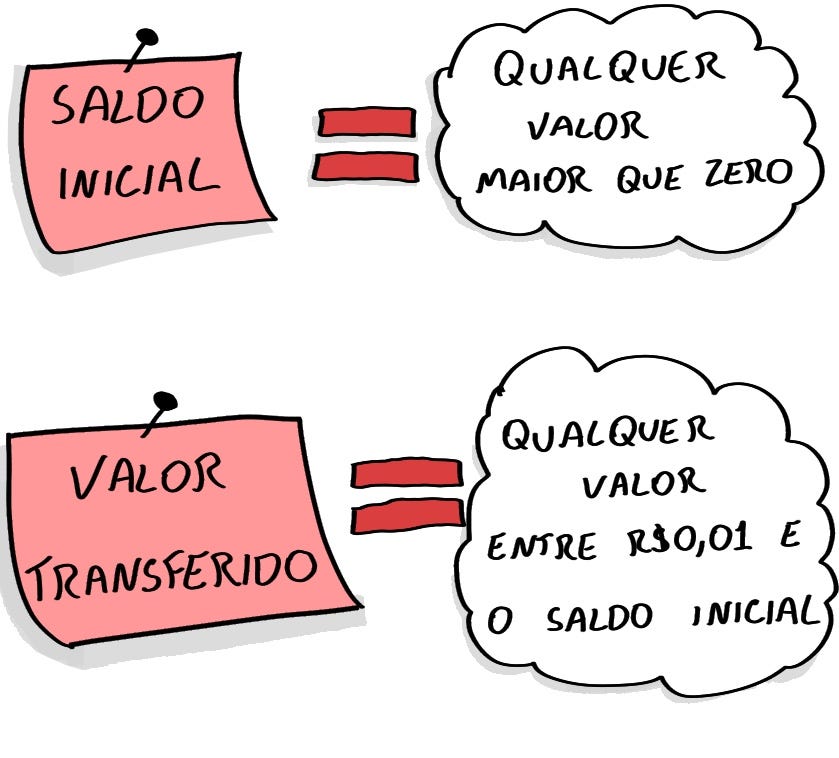
 Oops! If I have R$0.98 and try to transfer R$0.71 the problem also happens!
Oops! If I have R$0.98 and try to transfer R$0.71 the problem also happens! Image created by
Image created by 
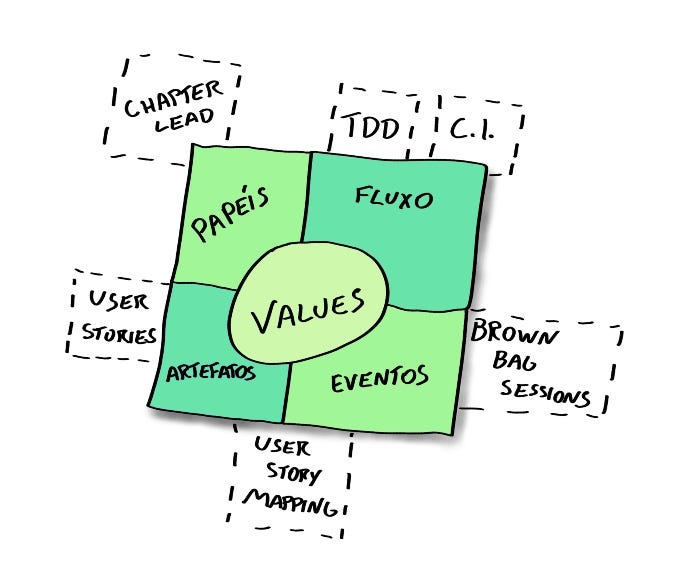 Representation of the Scrum framework completed by emerging techniques, created by Alexandre Magno
Representation of the Scrum framework completed by emerging techniques, created by Alexandre Magno E.T. Bilu would read the Scrum Guide before starting to use Scrum
E.T. Bilu would read the Scrum Guide before starting to use Scrum