Ora, torniamo alle nostre insidie e parliamo anche di una “guerra” che va avanti da 40 anni: la Guerra degli Editor. Potrebbe sembrare una guerra sciocca, o una semplice questione di preferenze, ma fidati: non è solo tribalismo geek, riguarda filosofie fondamentalmente diverse dell’interazione uomo-computer.
Sono un utente NeoVim. Questo significa che sono uno di quei geek che preferisce digitare codice nel terminale invece di usare qualcosa di più moderno come VSCode. Mentre uso NeoVim non uso mai il mouse o il touchpad: digito solo cose e uso un mucchio di combinazioni di tasti per navigare nel codice. Ma non sono solo! Il primo editor Vi è stato creato nel 1976 e da allora la sua popolarità è solo cresciuta tra i più geek degli sviluppatori software.
Perché? Beh, spieghiamolo mentre parliamo di una delle insidie che ho menzionato a Monaco:
Insidia 4: La Visione a Tunnel nella Codifica
Vi e i suoi fratelli (Vim, Neovim) sono diventati popolari perché permettevano agli sviluppatori di navigare nel codice più velocemente. Invece di muovere la mano verso il mouse, scorrere verso il basso, selezionare una parte del codice che vuoi cambiare e poi digitare il cambiamento, questi editor hanno proposto un’idea diversa: avrebbero avuto modalità. Mentre in modalità INSERT, tutto quello che digiti sulla tastiera apparirebbe sullo schermo, proprio come succede in qualsiasi altro editor. Ma in modalità NORMAL, ogni tasto sulla tastiera può essere usato per navigare nel codice.
Per esempio: se premi 3wce cambieresti istantaneamente il contenuto della terza parola in quella riga. (Qualcosa come: Vai alla 3a Word Change fino al suo End).
Fondamentalmente crea un dialetto così puoi dire al tuo editor dove vuoi andare e cosa vuoi fare con il tuo codice senza dover usare mouse, menu, ecc. E accelerare come navighiamo nel codice è importante perché gli sviluppatori software passano più tempo a navigare e capire il codice che a scriverlo.
Un grafico che rappresenta i risultati di una ricerca su come gli sviluppatori passano il loro tempo
Quindi, perché ci stiamo concentrando sull’uso degli LLM per generare codice quando possiamo anche usarli per aiutarci a capire il codice? Voglio dire, sono ottimi programmatori, non lo nego. Ma nella mia esperienza possono fornire molto più valore spiegando il codice invece di crearlo.
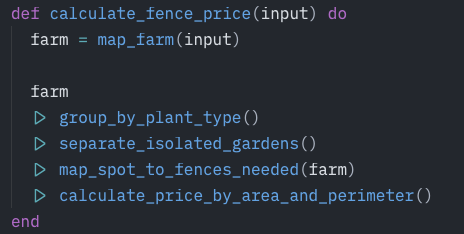
Ecco un esempio pratico di come l’ho fatto: sto attualmente scrivendo un software per migliorare le attività pratiche che faccio nelle mie classi. E a un certo punto ho deciso di chiedere a Claude di spiegarmi la mia stessa architettura. Dato che Claude eccelle nell’output testuale ho pensato che sarebbe stato bello usare uno strumento come Mermaid, uno strumento che trasforma input testuali in diagrammi ordinati. Ho chiesto a Claude di spiegare la struttura usando MarkDown e Mermaid, e ho incollato il risultato in un editor di testo compatibile con entrambe le tecnologie chiamato Typora. Ecco il risultato:
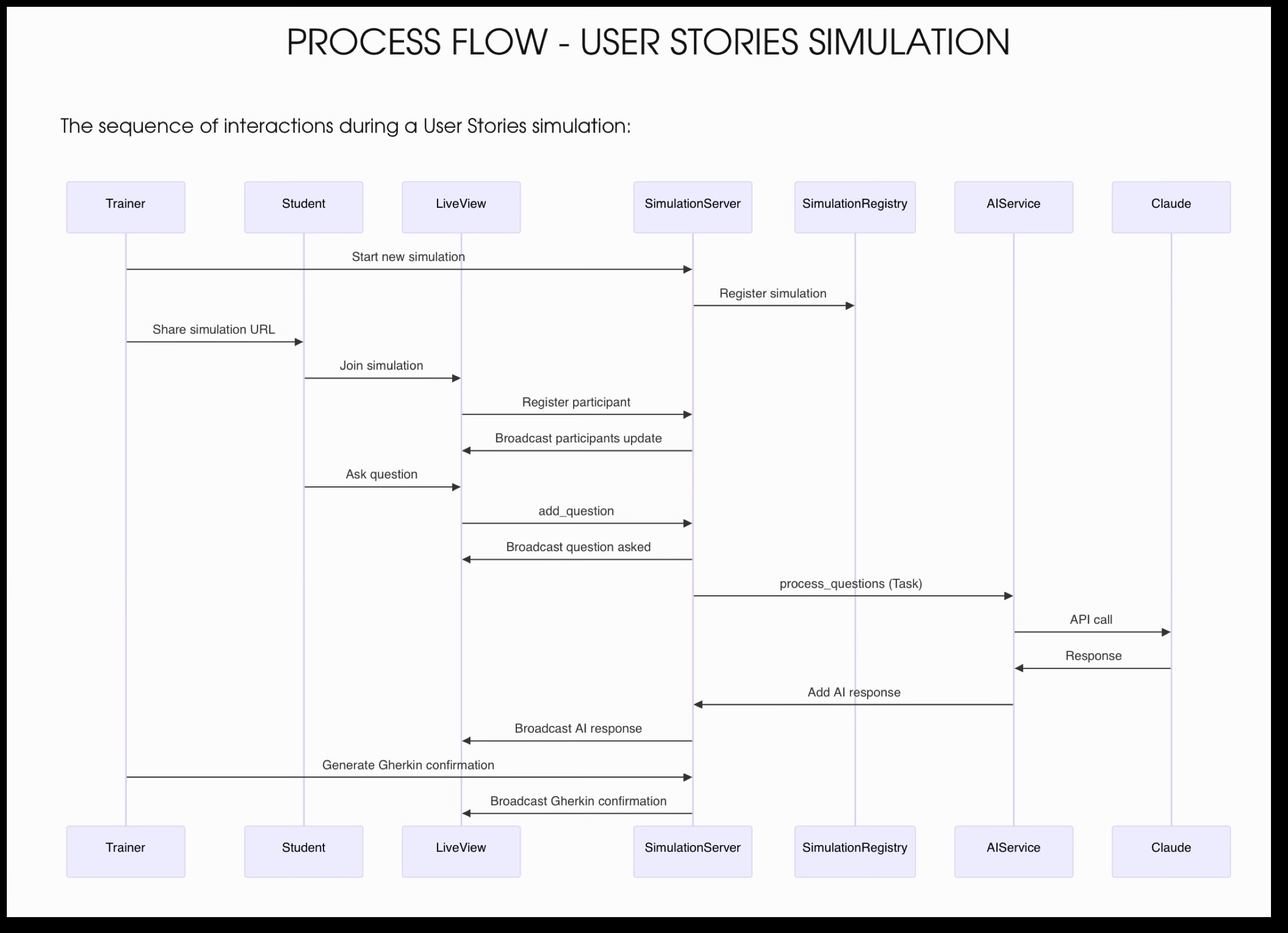
Questa è un’ottima documentazione che può essere usata per spiegare sia agli sviluppatori del mio team che allo stesso LLM come funziona l’architettura! Specialmente perché il diagramma può essere letto dall’LLM come un semplice input testuale, minimizzando la quantità di token consumati in ogni interazione.
Il punto è che, non importa se hai scritto il codice manualmente o se un LLM ha scritto l’intera cosa per te, sarai comunque responsabile delle conseguenze. Quindi, capire cosa sta succedendo è fondamentalmente importante.
Ricorda: se qualcosa funziona e non sai come, quando smette di funzionare non saprai perché.
Insidia 5: Il Bias del Volume
Alcune persone si lamentano ancora della qualità del codice generato dagli LLM e sono fortemente in disaccordo con questa opinione. Nella mia esperienza, il codice generato è in realtà piuttosto buono.
Quello che mi disturba è la quantità di codice.
Specialmente perché non credo nel “vibe coding” (cioè: fidarsi del codice generato e non dargli nemmeno un’occhiata). Devo revisionare il codice e assicurarmi che faccia quello che dovrebbe fare perché… sono un adulto responsabile? Quindi, quando l’LLM cambia 8 file e aggiunge 200 righe di codice per ogni prompt che faccio, il mio lavoro diventa estremamente doloroso e beh, noioso. Ho provato molteplici approcci e prompt diversi per ridurre questo problema ma devo ancora trovare una soluzione.
Per essere onesto Claude 4.0 ha presentato un grande miglioramento quando si tratta di questa particolare insidia, e penso che avremo una soluzione definitiva a questo in un futuro prossimo. Ma non ci siamo ancora.
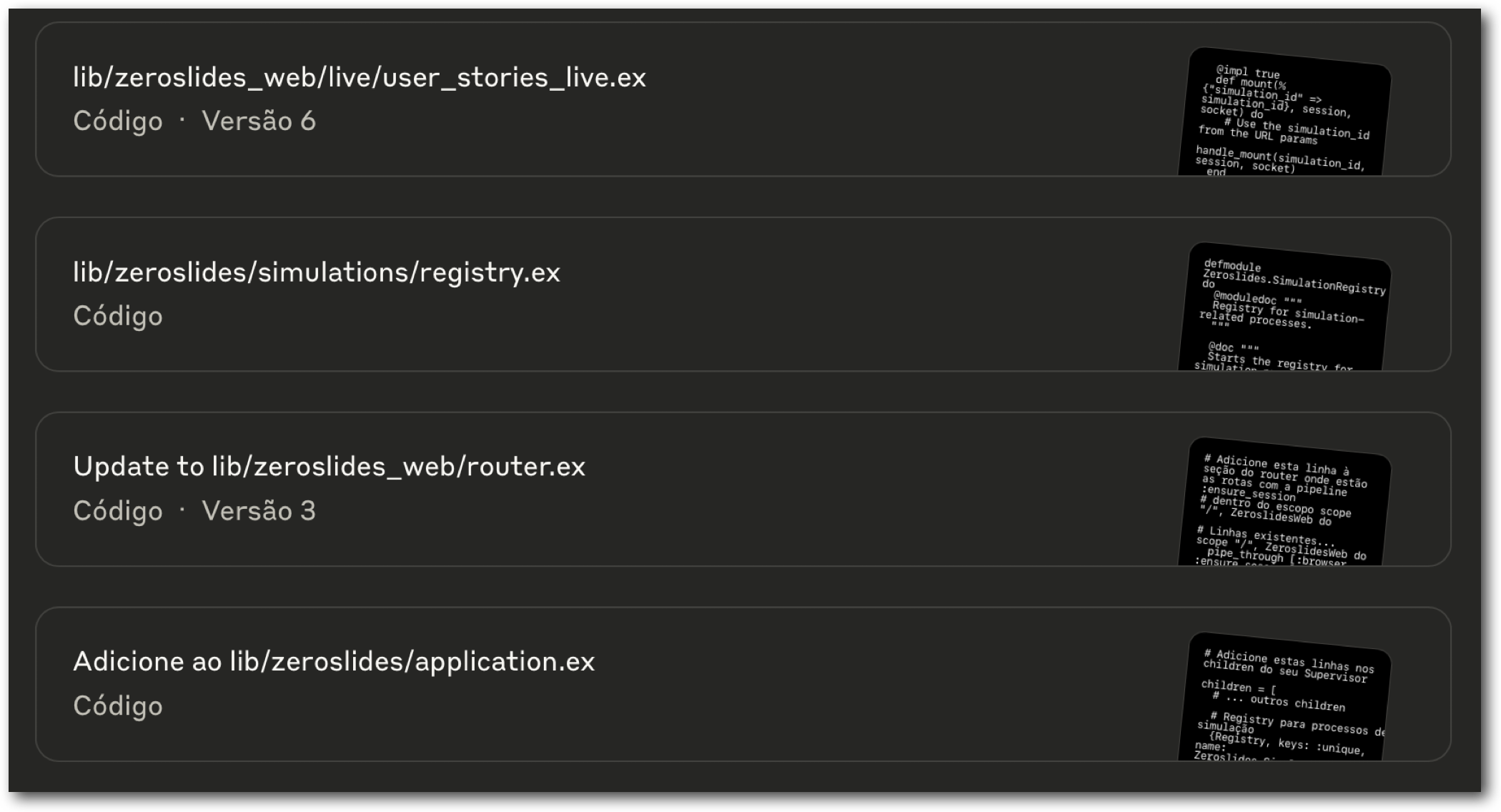 Un prompt, MOLTI cambiamenti
Un prompt, MOLTI cambiamenti
Quello che sento è che invece di aiutarci a camminare più velocemente gli LLM ci stanno aiutando a fare passi più grandi. Entrambi gli approcci possono aiutarci a coprire una distanza maggiore nella stessa quantità di tempo, ma il secondo comporta anche un alto costo quando stai camminando nella direzione sbagliata. Anche il modello di business contribuisce a questo: quando uso Cursor per esempio, ho token/interazioni limitati, il che mi incentiva a trarre il massimo da ogni prompt.
Conclusione
Scrivere sul lavorare con gli LLM è una cosa strana. Credo sinceramente in tutto quello che ho scritto in questo post oggi. Ma le cose stanno cambiando velocemente, e questo post potrebbe invecchiare come latte o vino a seconda dei prossimi sviluppi. Se apprezzi imparare di più su questo argomento, ti suggerisco fortemente di fare due cose: usalo per creare qualcosa invece di solo leggerne su LinkedIn (ancora meglio: allontanati del tutto da LinkedIn), e prova a leggere opinioni diverse sull’argomento. Il libro di Karen Hao “The Empire of AI” potrebbe essere un buon inizio.
]]> Il lato oscuro del vibe
Il lato oscuro del vibe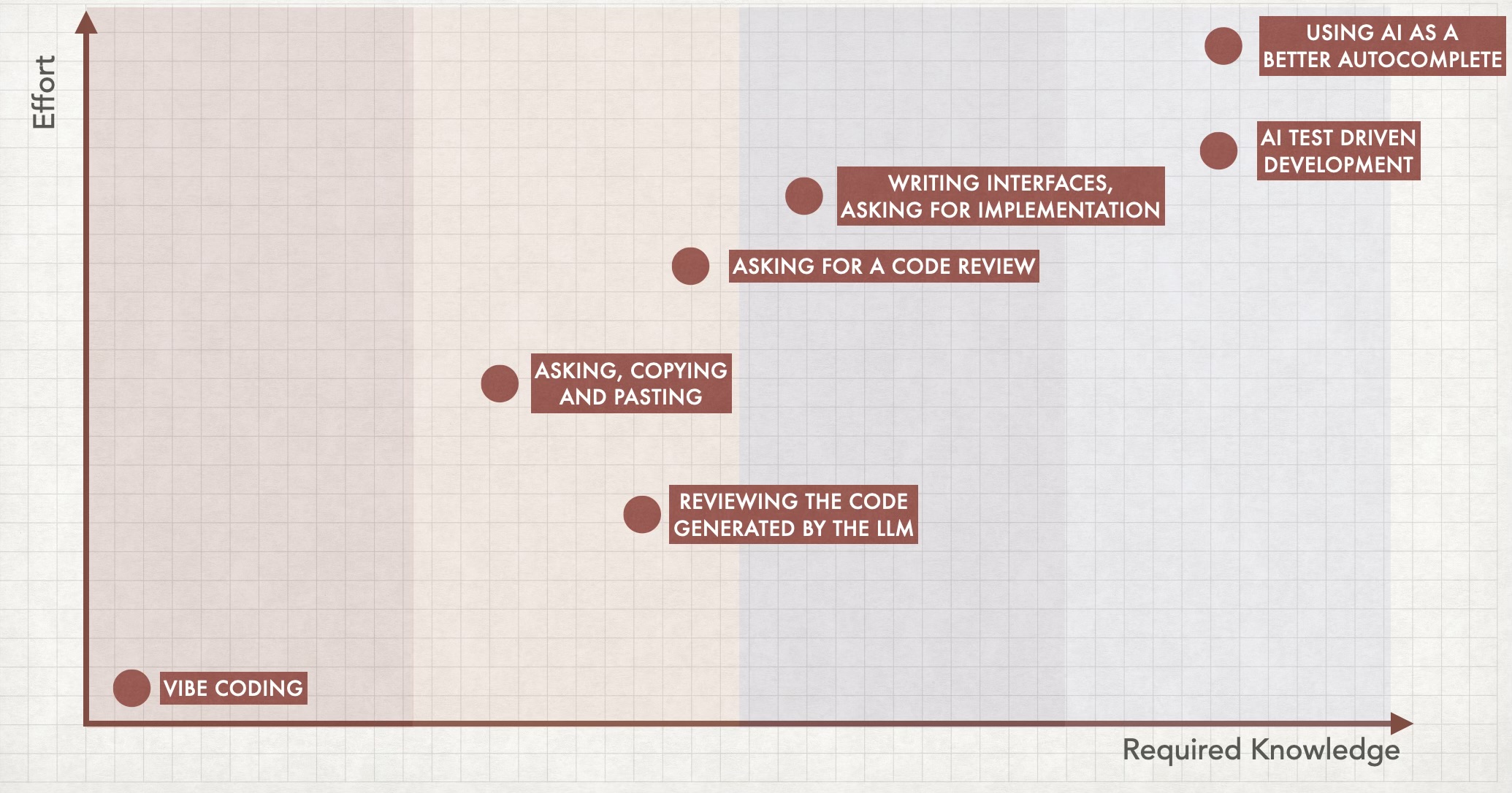 Una slide del mio intervento: Se hai più conoscenza tecnica, avrai più opzioni
Una slide del mio intervento: Se hai più conoscenza tecnica, avrai più opzioni
 Mobile negli anni 2000: Questi dispositivi potevano far sembrare fragile il Nokia 3310
Mobile negli anni 2000: Questi dispositivi potevano far sembrare fragile il Nokia 3310 La dipendenza da un’applicazione OTP è un po’ diversa.
La dipendenza da un’applicazione OTP è un po’ diversa.
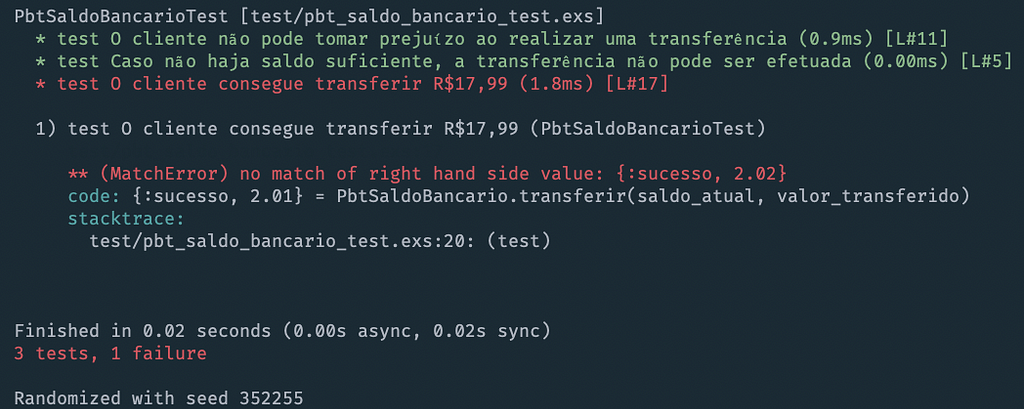 Il test fallisce perché il saldo rimanente era R$2,02 e non R$2,01
Il test fallisce perché il saldo rimanente era R$2,02 e non R$2,01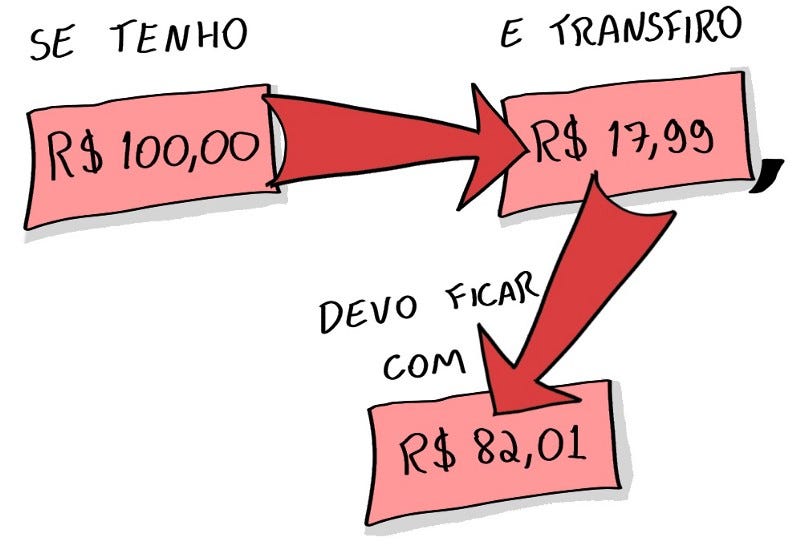
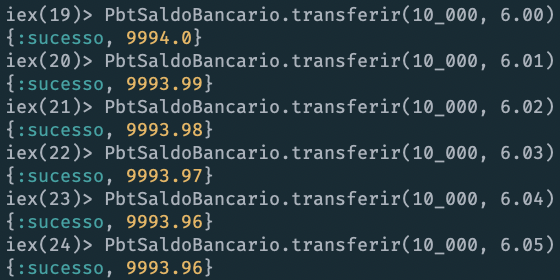 In questo caso, il problema è apparso solo quando si è provato a trasferire R$6,05
In questo caso, il problema è apparso solo quando si è provato a trasferire R$6,05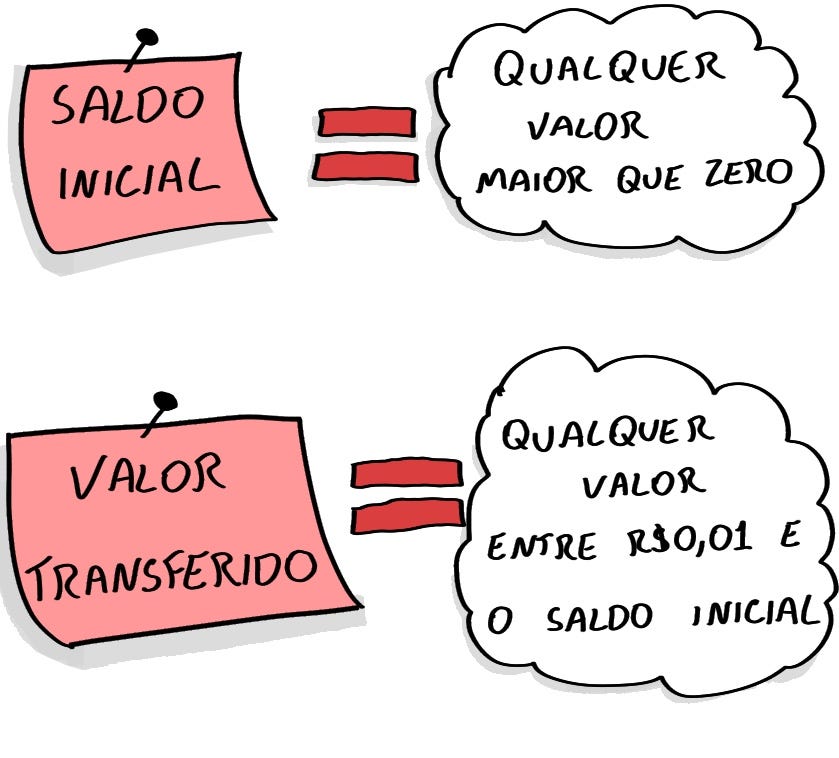
 Ops! Se ho R$0,98 e provo a trasferire R$0,71 il problema si verifica anche!
Ops! Se ho R$0,98 e provo a trasferire R$0,71 il problema si verifica anche!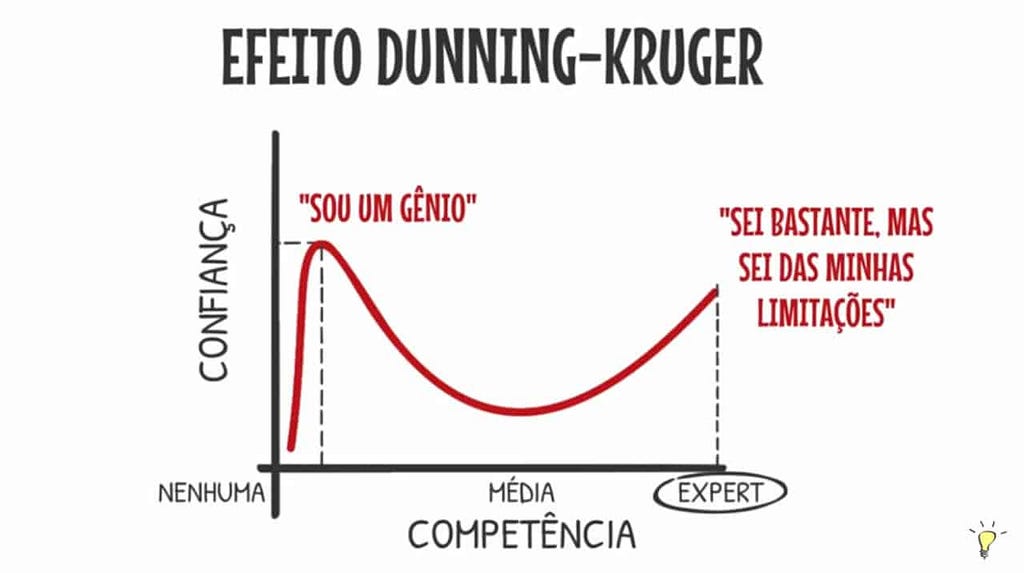 Immagine creata da
Immagine creata da 
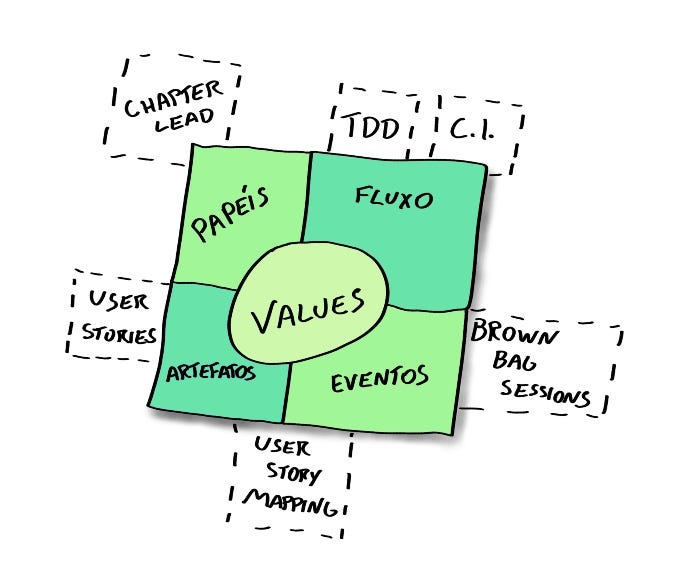 Rappresentazione del framework Scrum completato da tecniche emergenti, creata da Alexandre Magno
Rappresentazione del framework Scrum completato da tecniche emergenti, creata da Alexandre Magno E.T. Bilu leggerebbe lo Scrum Guide prima di iniziare a usare Scrum
E.T. Bilu leggerebbe lo Scrum Guide prima di iniziare a usare Scrum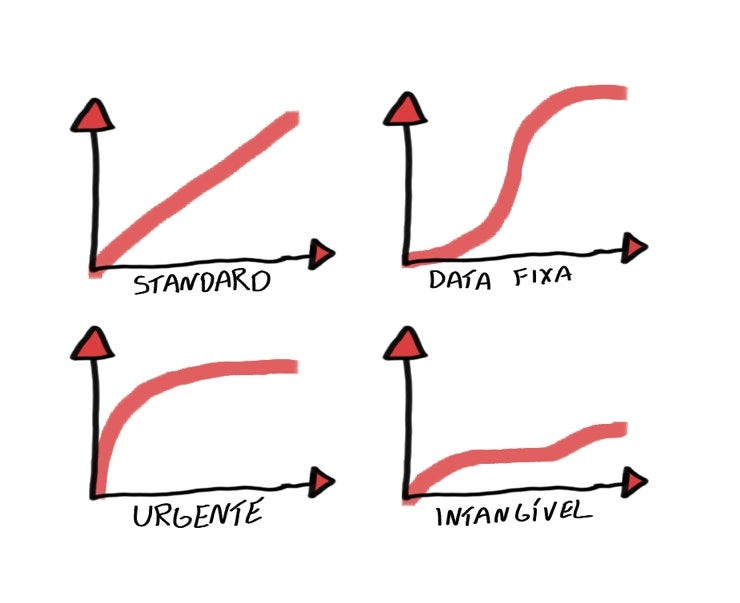
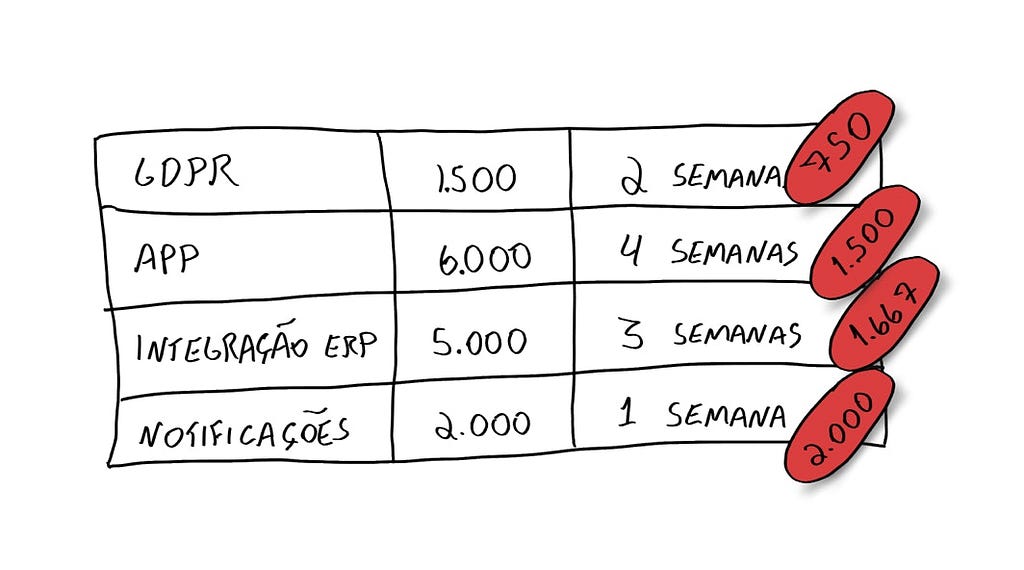
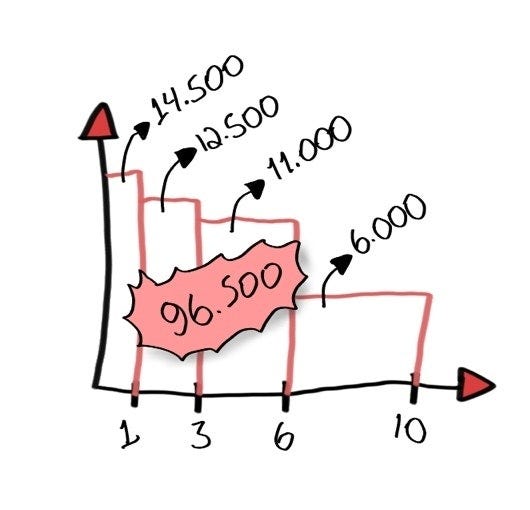
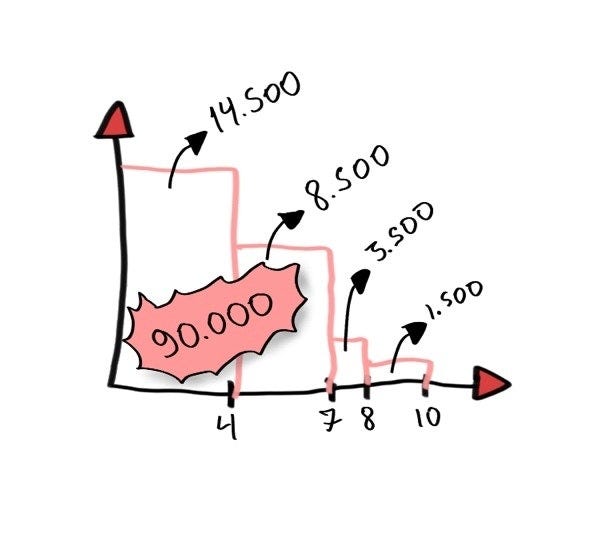
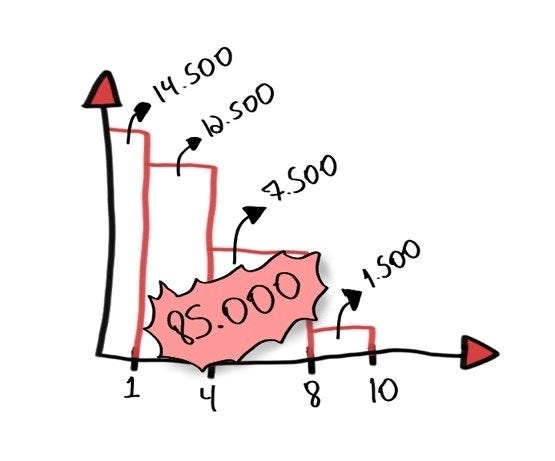

 Ecco come appare un Product Backlog iniziale in Scrumchkin
Ecco come appare un Product Backlog iniziale in Scrumchkin I Bug sono fastidiosi. Inoltre, URGENTE!
I Bug sono fastidiosi. Inoltre, URGENTE! I Bug, come ogni famoso cattivo, hanno la loro kryptonite
I Bug, come ogni famoso cattivo, hanno la loro kryptonite Ci sono anche Carte Feedback buone, lo prometto
Ci sono anche Carte Feedback buone, lo prometto