
Minha palestra no Global Scrum Gathering Munich foi rápida, e eu disse lá que escreveria sobre o assunto para aprofundar essa discussão, então aqui estou. Adicionei uma “Parte 1” ao título porque agora gostaria de explorar três delas: Fixação na Escrita, Abordagem Monolítica e Atrofia para Aprender.
A coisa engraçada nessa conferência é que fui a duas palestras subsequentes que se conectaram diretamente com o que apresentei: Nigel Baker e Paul Goddard falaram sobre Pair Programming (e ainda estou decepcionado que eles não mencionaram Penn & Teller nos seus exemplos de pareamento) e o keynote final do Henrik Kniberg que falou sobre IA agêntica em software e desenvolvimento ágil de software. Então, também vou conectar insights das apresentações deles para enriquecer nossa conversa. Para fazer isso, vou mudar a ordem em que inicialmente apresentei as armadilhas.
Armadilha 1 - Fixação na Escrita
Minha primeira reclamação sobre como a maioria das pessoas tem usado IA era sobre como continuamos escrevendo e usando texto como a única forma de falar com nossos LLMs. Kniberg usou duas formas diferentes de comunicação durante sua apresentação: voz e um desenho em guardanapo. E é precisamente sobre isso que eu estava falando: a linguagem tem limitações, e essas são notícias velhas. Nietzsche notoriamente disse que Toda palavra é um preconceito e William James desafiou nossa capacidade de compreender o significado por trás das palavras com sua anedota do esquilo dando volta na árvore.
Se você quiser experimentar como isso poderia funcionar, você pode integrar o Aider com ChatGPT para usar sua voz para programar (e talvez esse possa ser meu próximo post também). Mas se você não quiser ir tão longe, desenhe, tire screenshots para usar como exemplos, basicamente: experimente.
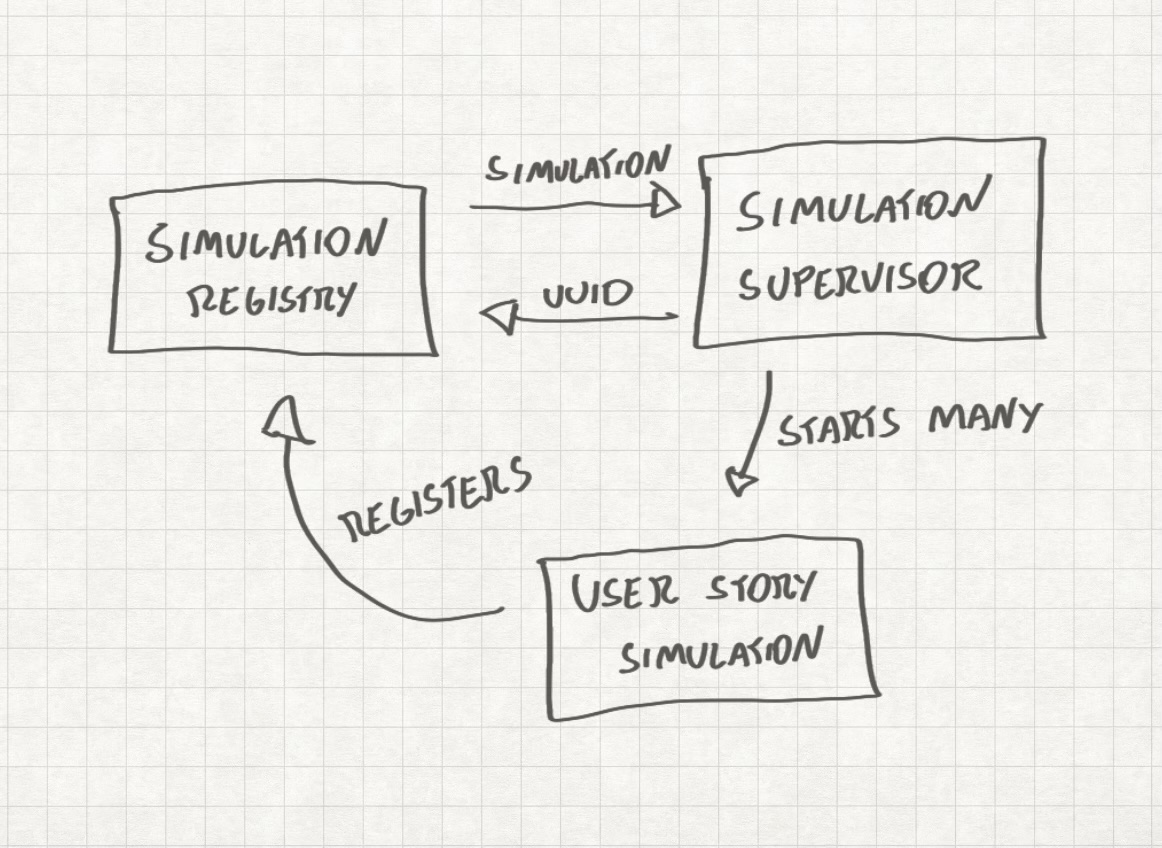
Um diagrama mostrando como os módulos da minha aplicação devem interagir entre si
Agora, o diagrama nos leva imediatamente para a próxima armadilha…
Armadilha 2 - Atrofia para Aprender
Se uma IA pode programar, por que eu aprenderia a programar?, bem… essa é uma pergunta interessante. Na minha palestra mencionei que o código gerado pelos LLMs atuais (como Sonnet 3.7) é na verdade muito bom, e muitas vezes melhor do que o que um humano escreveria. E os LLMs estão melhorando mais rápido do que nós estamos agora, então…
Então ainda precisamos aprender. Olhe o diagrama na seção anterior: ele fala sobre estrutura de software e como organizar o código. Se você não sabe programar, você não consegue criar diagramas como esses e suas opções serão limitadas. Essas limitações podem te levar a becos sem saída e problemas que você é incapaz de resolver, e se seu colega IA também é incapaz de resolver então…
 O lado sombrio do vibe
O lado sombrio do vibe
Como Nigel Baker e Paul Goddard disseram na palestra deles: parear é uma ótima forma de aprender. Você provavelmente vai aprender que pessoas diferentes usam LLMs de formas diferentes, e você vai ter que descobrir quando usar cada abordagem. Por exemplo: hoje em dia você pode literalmente programar um agente que checaria tudo que sua pessoa amada postou na internet e automaticamente compraria presentes para ela em datas especiais. E provavelmente serão bons presentes!
Mas é uma boa ideia? Bem, eu não acho. Simon Wardley propõe uma pergunta interessante para resolver esse dilema, e em todo caso, se você ainda não assistiu a palestra dele por favor assista:
Quanto você valoriza um humano envolvido nessa decisão?
E às vezes, quando desenvolvemos software, isso importa. Mas novamente: suas capacidades de tomada de decisão serão limitadas pelo seu conhecimento. Então, continue aprendendo (e tente parear com outra pessoa para que você possa aprender mais e mais rápido).
Armadilha 3 - A Abordagem Monolítica
Eu fiz uma piada durante minha apresentação e disse que Vibe Coding deveria ser renomeado para Conversational Reactive Assisted Programming, ou C.R.A.P.. Todo mundo riu, e momentos depois estávamos todos assistindo Henrik Kniberg fazendo uma demonstração impressionante usando Cursor.
Então, acho que vou ter que me explicar. :)
O termo Vibe Coding foi cunhado por Andrej Karpathy, e ele disse que a técnica é “não tão ruim para projetos descartáveis de fim de semana”. Uma parte chave da definição de vibe coding é que o usuário aceita código sem entendimento completo, e o pesquisador de IA Simon Willison até disse que “Se um LLM escreveu cada linha do seu código, mas você revisou, testou e entendeu tudo, isso não é vibe coding no meu entendimento—isso é usar um LLM como um assistente de digitação.”
Então, por essa definição de Vibe Coding, eu mantenho minha piada. Pelo menos por enquanto. O conceito de não se importar com o código gerado por um LLM pode ser uma boa ideia, mas apenas se soubermos quando usá-lo, e por enquanto não deveria ser 100% do tempo a menos que você esteja construindo um protótipo.
A questão é que, se você não sabe programar, Vibe Coding será sua única opção quando usar um LLM para desenvolver software. E não é realmente programação, porque é não-determinístico: o mesmo prompt pode gerar resultados diferentes. Eu prefiro o termo que Simon Wardley usa: Vibe Wrangling.
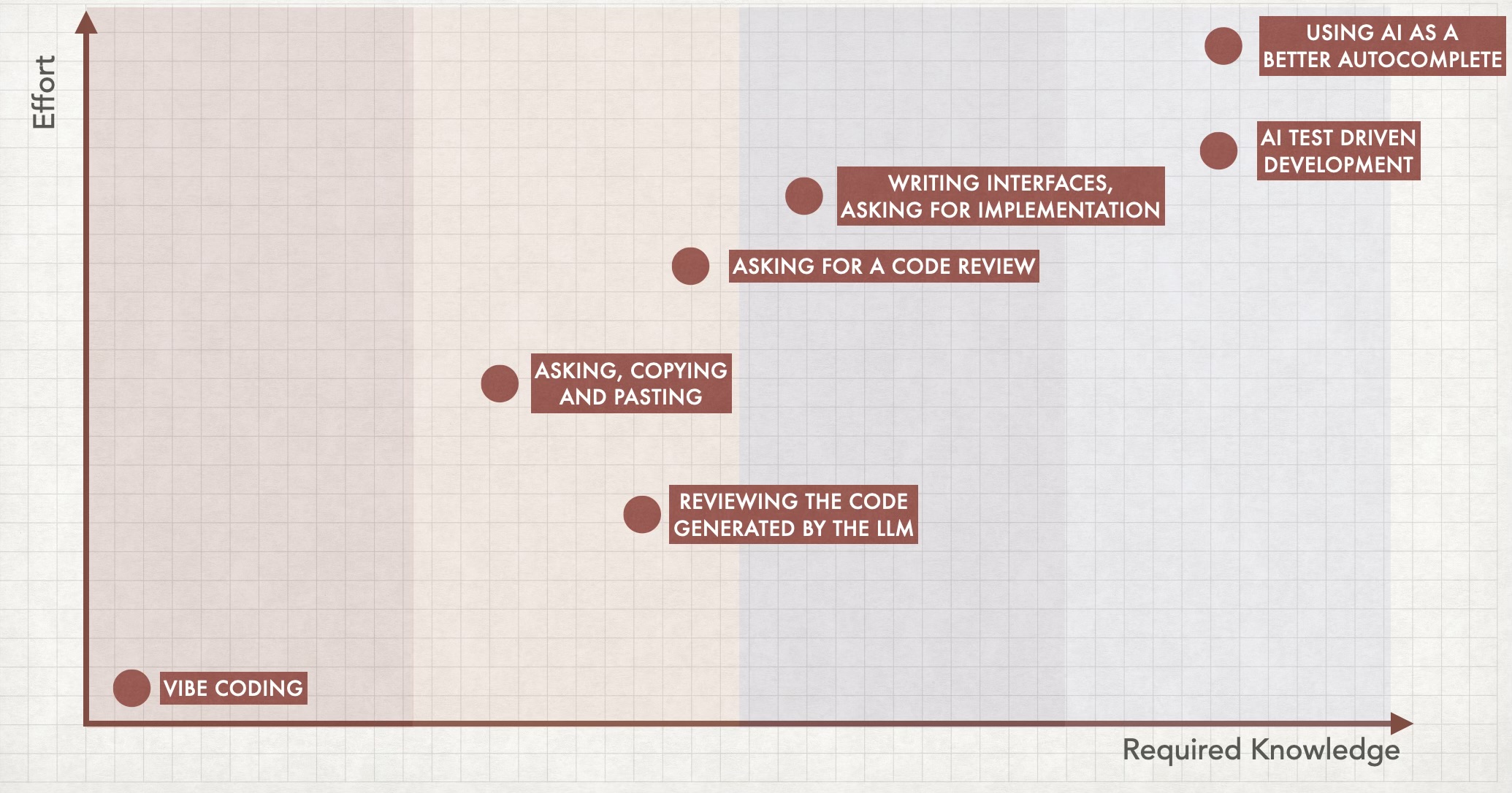 Um slide da minha palestra: Se você tem mais conhecimento técnico, você terá mais opções
Um slide da minha palestra: Se você tem mais conhecimento técnico, você terá mais opções
Talvez no futuro ter Vibe Coding como sua única opção não será um problema, mas ainda não chegamos lá. Pode acontecer ano que vem, em 2035, ou pode nunca acontecer. Mas não importa a resposta, aprender a programar ainda é relevante porque vai expandir suas opções. E essa é minha principal (e talvez única) crítica sobre a ótima sessão de keynote do Kniberg: eu não acho que Vibe Coding é uma evolução de copiar e colar código gerado por um LLM, por exemplo. Eu vejo todas essas abordagens sendo usadas em contextos diferentes, e a decisão sempre vai se resumir a uma versão levemente modificada da pergunta proposta por Simon Wardley:
Quão consciente eu preciso estar sobre a forma como isso vai ser implementado?
Para mim a resposta ainda é “com bastante frequência”. LLMs são enviesados, não-determinísticos e replicam todos os problemas que estavam presentes em seus dados de treinamento. Eles vão cometer erros, e alguns desses erros podem prejudicar pessoas, especialmente em grupos que são sub-representados nos dados usados para treinar os modelos (você pode e deve conferir o trabalho da Dra. Timnit Gebru). Quando aceitamos código gerado por IA sem entendimento completo, estamos herdando não apenas a solução, mas também os preconceitos conceituais embutidos nela.
Então, responder essa pergunta é algo que vamos começar a fazer cada vez mais. E voltando à sessão de Nigel Baker e Paul Goddard: você não precisa responder essa pergunta sozinho.


{kind=link}