
Il mio intervento al Global Scrum Gathering Munich è stato veloce, e ho detto lì che avrei scritto sull’argomento per approfondire questa discussione, quindi eccomi qui. Ho aggiunto una “Parte 1” al titolo perché ora vorrei esplorarne tre: Fissazione sulla Scrittura, Approccio Monolitico e Atrofia nell’Apprendere.
La cosa divertente di questa conferenza è che sono andato a due interventi successivi che si collegavano direttamente a quello che ho presentato: Nigel Baker e Paul Goddard hanno parlato di Pair Programming (e sono ancora deluso che non abbiano menzionato Penn & Teller nei loro esempi di pairing) e il keynote finale di Henrik Kniberg che ha parlato di IA agentica nel software e nello sviluppo software agile. Quindi, collegherò anche insight dalle loro presentazioni per arricchire la nostra conversazione. Per farlo, cambierò l’ordine in cui ho inizialmente presentato le insidie.
Insidia 1 - Fissazione sulla Scrittura
La mia prima lamentela su come la maggior parte delle persone ha usato l’IA riguardava come continuiamo a scrivere e usare il testo come l’unico modo per parlare con i nostri LLM. Kniberg ha usato due forme diverse di comunicazione durante la sua presentazione: voce e un disegno su tovagliolo. Ed è proprio di questo che stavo parlando: il linguaggio ha limitazioni, e queste sono vecchie notizie. Nietzsche ha notoriamente detto che Ogni parola è un pregiudizio e William James ha sfidato la nostra capacità di comprendere il significato dietro le parole con il suo aneddoto dello scoiattolo che gira intorno all’albero.
Se vuoi provare come potrebbe funzionare, puoi integrare Aider con ChatGPT per usare la tua voce per programmare (e forse questo potrebbe essere il mio prossimo post). Ma se non vuoi spingerti così lontano, disegna, fai screenshot da usare come esempi, fondamentalmente: sperimenta.
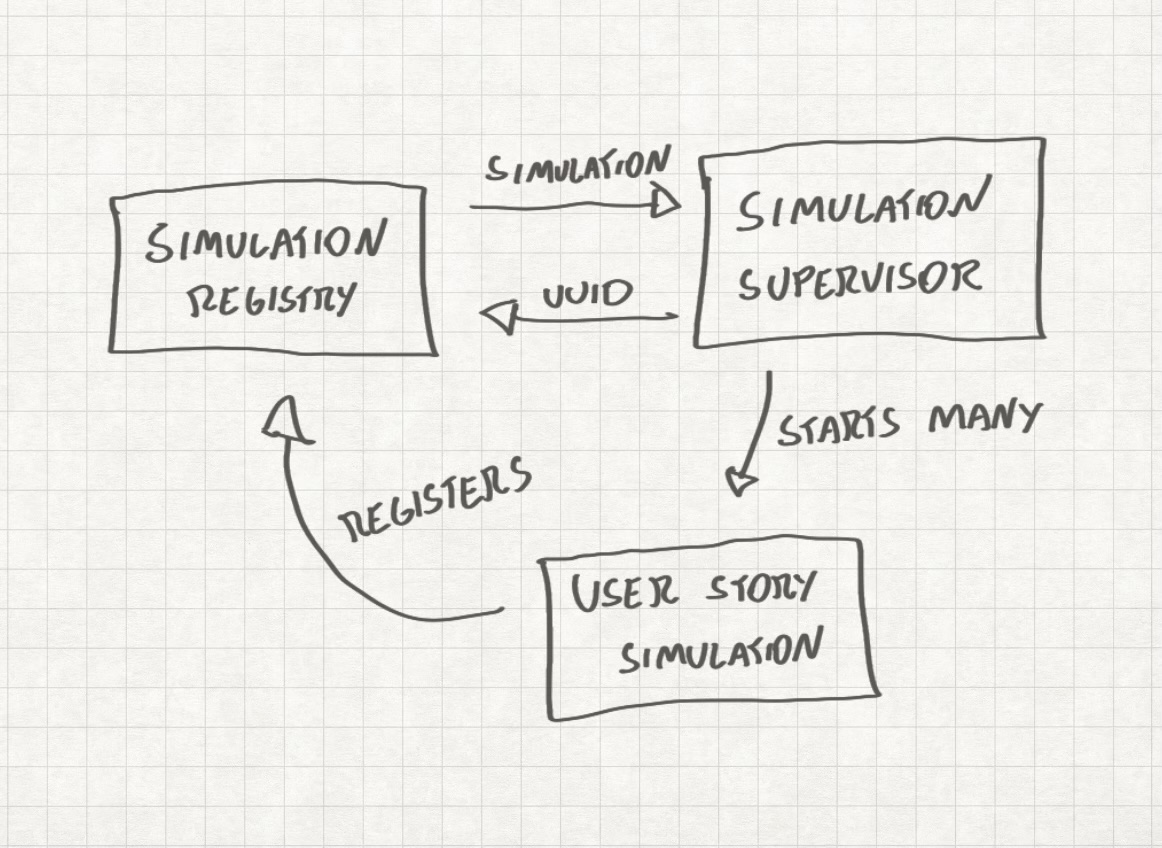
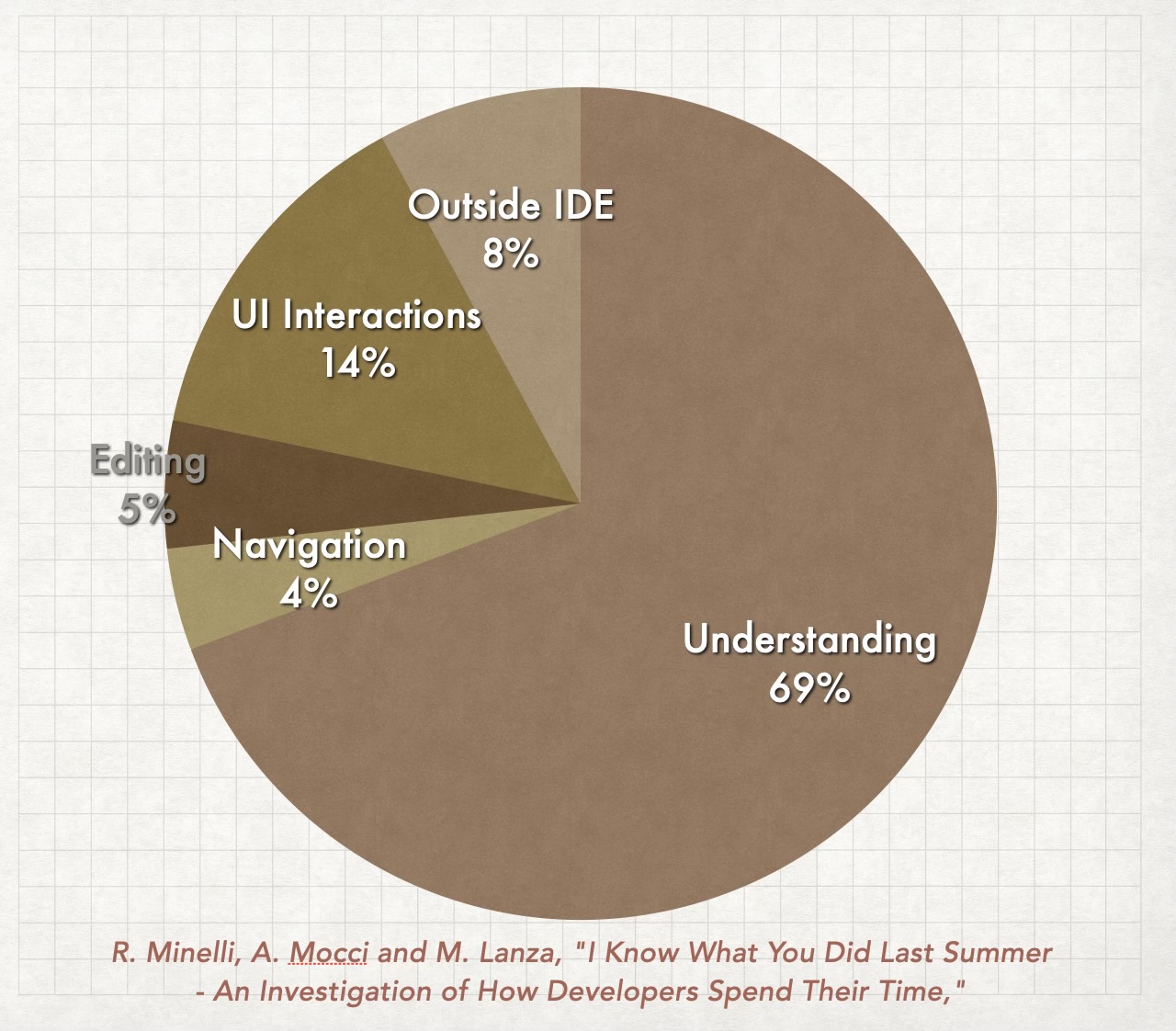
Un diagramma che mostra come i moduli della mia applicazione dovrebbero interagire tra loro
Ora, il diagramma ci porta immediatamente alla prossima insidia…
Insidia 2 - Atrofia nell’Apprendere
Se un’IA può programmare, perché dovrei imparare a programmare?, beh… questa è una domanda interessante. Nel mio intervento ho menzionato che il codice generato dagli attuali LLM (come Sonnet 3.7) è in realtà piuttosto buono, e spesso migliore di quello che scriverebbe un umano. E gli LLM stanno migliorando più velocemente di noi in questo momento, quindi…
Quindi dobbiamo ancora imparare. Guarda il diagramma nella sezione precedente: parla di struttura software e come organizzare il codice. Se non sai programmare, non puoi creare diagrammi come questi e le tue opzioni saranno limitate. Queste limitazioni possono portarti a vicoli ciechi e problemi che non sei in grado di risolvere, e se anche il tuo collega IA non è in grado di risolverli allora…
 Il lato oscuro del vibe
Il lato oscuro del vibe
Come hanno detto Nigel Baker e Paul Goddard nel loro intervento: il pairing è un ottimo modo per imparare. Probabilmente imparerai che persone diverse usano gli LLM in modi diversi, e dovrai capire quando usare ogni approccio. Per esempio: al giorno d’oggi puoi letteralmente programmare un agente che controllerebbe tutto quello che il tuo partner ha postato su internet e comprerebbe automaticamente regali per loro in date speciali. E probabilmente saranno buoni regali!
Ma è una buona idea? Beh, non credo. Simon Wardley propone una domanda interessante per risolvere questo dilemma, e in ogni caso, se non hai ancora visto il suo intervento per favore fallo:
Quanto valorizzi un umano coinvolto in quella decisione?
E a volte, quando sviluppi software, conta. Ma ancora una volta: le tue capacità decisionali saranno limitate dalla tua conoscenza. Quindi, continua a imparare (e prova a fare pairing con qualcun altro così puoi imparare di più e più velocemente).
Insidia 3 - L’Approccio Monolitico
Ho fatto una battuta durante la mia presentazione e ho detto che Vibe Coding dovrebbe essere rinominato Conversational Reactive Assisted Programming, o C.R.A.P.. Tutti hanno riso, e momenti dopo stavamo tutti guardando Henrik Kniberg fare un’impressionante dimostrazione usando Cursor.
Quindi, penso che dovrò spiegarmi. :)
Il termine Vibe Coding è stato coniato da Andrej Karpathy, e ha detto che la tecnica è “non troppo male per progetti usa e getta del weekend”. Una parte chiave della definizione di vibe coding è che l’utente accetta il codice senza piena comprensione, e il ricercatore di IA Simon Willison ha persino detto che “Se un LLM ha scritto ogni riga del tuo codice, ma l’hai revisionato, testato e capito tutto, questo non è vibe coding secondo me—questo è usare un LLM come assistente di digitazione.”
Quindi, per quella definizione di Vibe Coding, mantengo la mia battuta. Almeno per ora. Il concetto di non preoccuparsi del codice generato da un LLM può essere una buona idea, ma solo se sappiamo quando usarlo, e per ora non dovrebbe essere il 100% del tempo a meno che tu non stia costruendo un prototipo.
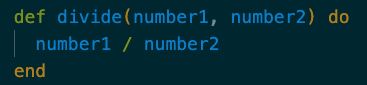
Il punto è che, se non sai programmare, il Vibe Coding sarà la tua unica opzione quando usi un LLM per sviluppare software. E non è veramente programmare, perché è non-deterministico: lo stesso prompt potrebbe generare risultati diversi. Preferisco il termine che usa Simon Wardley: Vibe Wrangling.
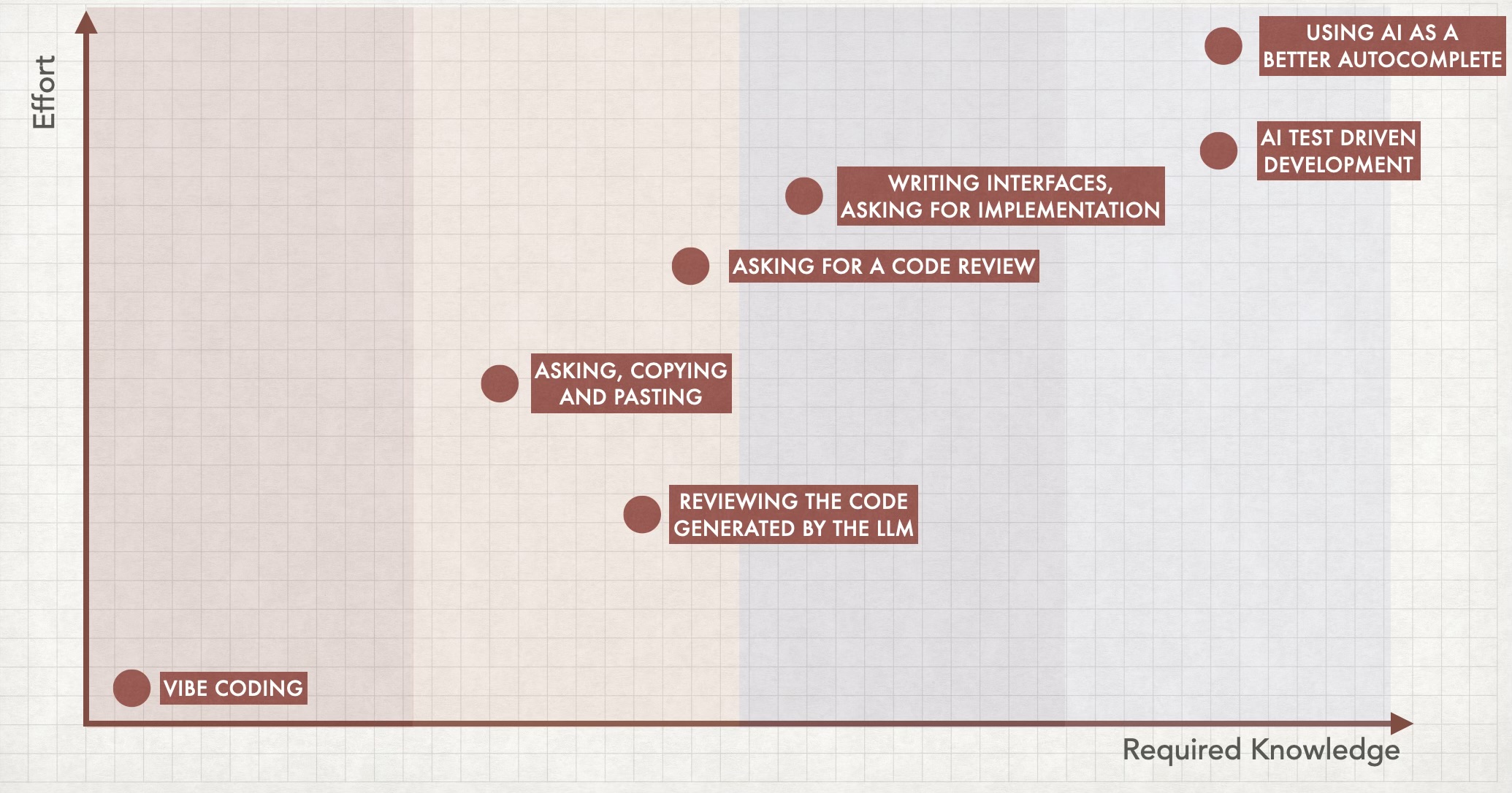 Una slide del mio intervento: Se hai più conoscenza tecnica, avrai più opzioni
Una slide del mio intervento: Se hai più conoscenza tecnica, avrai più opzioni
Forse in futuro avere il Vibe Coding come unica opzione non sarà un problema, ma non ci siamo ancora. Potrebbe succedere l’anno prossimo, nel 2035, o potrebbe non succedere mai. Ma qualunque sia la risposta, imparare a programmare è ancora rilevante perché espanderà le tue opzioni. E questa è la mia principale (e forse unica) critica sull’ottima sessione keynote di Kniberg: non penso che il Vibe Coding sia un’evoluzione del copiare e incollare codice generato da un LLM, per esempio. Vedo tutti questi approcci essere usati in contesti diversi, e la decisione si ridurrà sempre a una versione leggermente modificata della domanda proposta da Simon Wardley:
Quanto consapevole devo essere sul modo in cui questo verrà implementato?
Per me la risposta è ancora “abbastanza spesso”. Gli LLM sono biased, non-deterministici e replicano tutti i problemi che erano presenti nei loro dati di training. Faranno errori, e alcuni di questi errori potrebbero danneggiare le persone, specialmente in gruppi che sono sotto-rappresentati nei dati usati per addestrare i modelli (puoi e dovresti controllare il lavoro della Dott.ssa Timnit Gebru). Quando accettiamo codice generato dall’IA senza piena comprensione, stiamo ereditando non solo la soluzione ma anche i pregiudizi concettuali incorporati in essa.
Quindi, rispondere a quella domanda è qualcosa che inizieremo a fare sempre di più. E tornando alla sessione di Nigel Baker e Paul Goddard: non devi rispondere a quella domanda da solo.

{kind=link}