

Il tuo backlog non è obsoleto perché è passato del tempo. È obsoleto perché hai rilasciato.
Questa settimana ho finalmente messo in parole una conclusione che si stava formando da mesi nella mia mente confusa: lo sviluppo assistito da LLM ha probabilmente rotto una delle nostre metriche più affidabili: l’Età dell’Informazione (che è anche una delle mie metriche preferite). Eravamo abituati a misurare l’obsolescenza delle informazioni nel tempo, del tipo: “quell’elemento è stato raffinato tre settimane fa, probabilmente è obsoleto.” Questo non funziona più sempre. Una specifica può diventare obsoleta in un solo giorno, non perché il mondo sia cambiato, ma perché il team ha rilasciato sette incrementi dalla colazione (altre informazioni sulla scadenza delle informazioni qui).
Questa realizzazione mi ha portato a costruire pbl-skills, un plugin che mantiene il tuo Product Backlog all’interno della codebase e traccia una metrica che chiamo Increment Drift al posto dell’Età dell’Informazione.
Ecco come funziona:
pbl-skills e i suoi 4 principi
Il plugin si chiama pbl-skills e ci sono due modi per utilizzarlo. Se usi pi, digita semplicemente:
pi install -l npm:pbl-skills
Se stai usando un altro harness (come Claude Code o Codex) puoi comunque beneficiare delle skill. Sono disponibili su:
Repository Github di pbl-skills
Il plugin si basa su 4 principi che ho elaborato dopo due anni di sperimentazione con lo sviluppo aumentato da LLM. I primi due sono scelte architetturali, il terzo è un approccio alla documentazione e il quarto è probabilmente la scoperta più importante che ho fatto durante questo processo. Quindi, se non vuoi leggere l’intero post, vai direttamente al quarto principio.
Parliamo di ciascuno e colleghiamo ogni principio a una funzionalità implementata in pbl-skills.
Principio 1: Il Product Backlog deve vivere nel repository del codice
Semplice. Se stiamo usando gli LLM per sviluppare software, tutte le informazioni sul progetto devono risiedere nella cartella del progetto. Per questo il plugin ha un comando chiamato /pbl-kickoff che può prendere una breve frase o un file .md contenente l’idea del progetto e trasformarlo in un Product Backlog.
Il comando
/pbl-kickoffè stato ispirato dal comandogrill-mecreato da Matt Pocock.
Il Product Backlog viene creato nella cartella ./product-backlog, e ogni elemento ottiene una sottocartella dedicata che appare così:
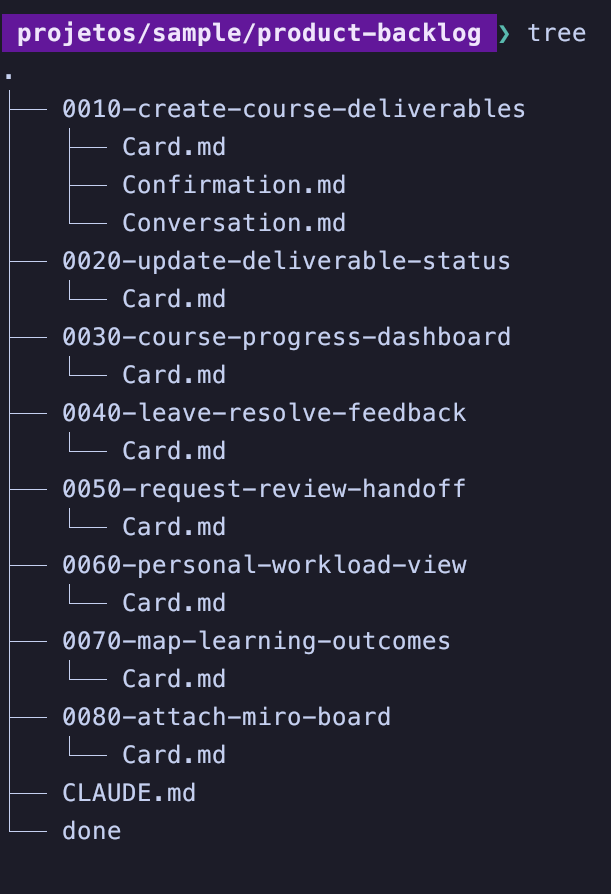
Il Product Backlog è anche ordinato, e utilizza numeri nei nomi delle cartelle per farlo. Semplice, ma funziona. Inoltre, gli elementi sono sempre fette verticali del prodotto.
A questo punto, l’LLM proporrà anche una Definizione di Done iniziale. Non è necessario essere troppo precisi qui, perché l’intento è creare uno standard di qualità che evolverà nel tempo.
Questo è un plugin decisamente opinionato: gli elementi utilizzeranno sempre le 3 C delle User Story e il formato Connextra, e questo ci aiuterà a tracciare lo stato del Product Backlog.
Gli elementi con solo un file Card.md nella cartella sono considerati Grezzi.
Gli elementi con Card.md e Conversation.md nella cartella sono elementi che stiamo ancora Raffinando.
Gli elementi con Card.md, Conversation.md e Confirmation.md nella cartella sono considerati Pronti.
Principio 2: Un elemento del backlog deve essere comprensibile in modo indipendente da un agente senza contesto pregresso
Non voglio che il mio contesto cresca indefinitamente. Voglio entrare e iniziare a raffinare un elemento. Ed è esattamente quello che succede quando esegui /pbl-refine: l’LLM prenderà l’elemento più in alto nel tuo Product Backlog e ti intervisterà finché non sarà soddisfatto delle informazioni.
Il comando
/pbl-refineè stato ispirato dal comandogrill-with-docscreato da Matt Pocock.
Se non hai abbastanza informazioni o interrompi la conversazione a metà, l’LLM creerà semplicemente un riassunto della conversazione in un file Conversation.md. Se rispondi a tutte le domande, l’LLM proporrà un file Confirmation.md. Qui, e in qualsiasi punto di questo processo, puoi dissentire e aggiungere qualcosa che l’LLM ha mancato.
Il file Confirmation.md è strutturato per essere una conferma idealmente eseguibile, facilmente trascrivibile in framework di test come RSpec, Jest, JUnit, ExUnit, ecc.
C’è anche un’altra skill che può essere invocata manualmente o suggerita dall’LLM: /pbl-split.
Il comando /pbl-split è stato ispirato dal metodo hamburger creato da Gojko Adzic
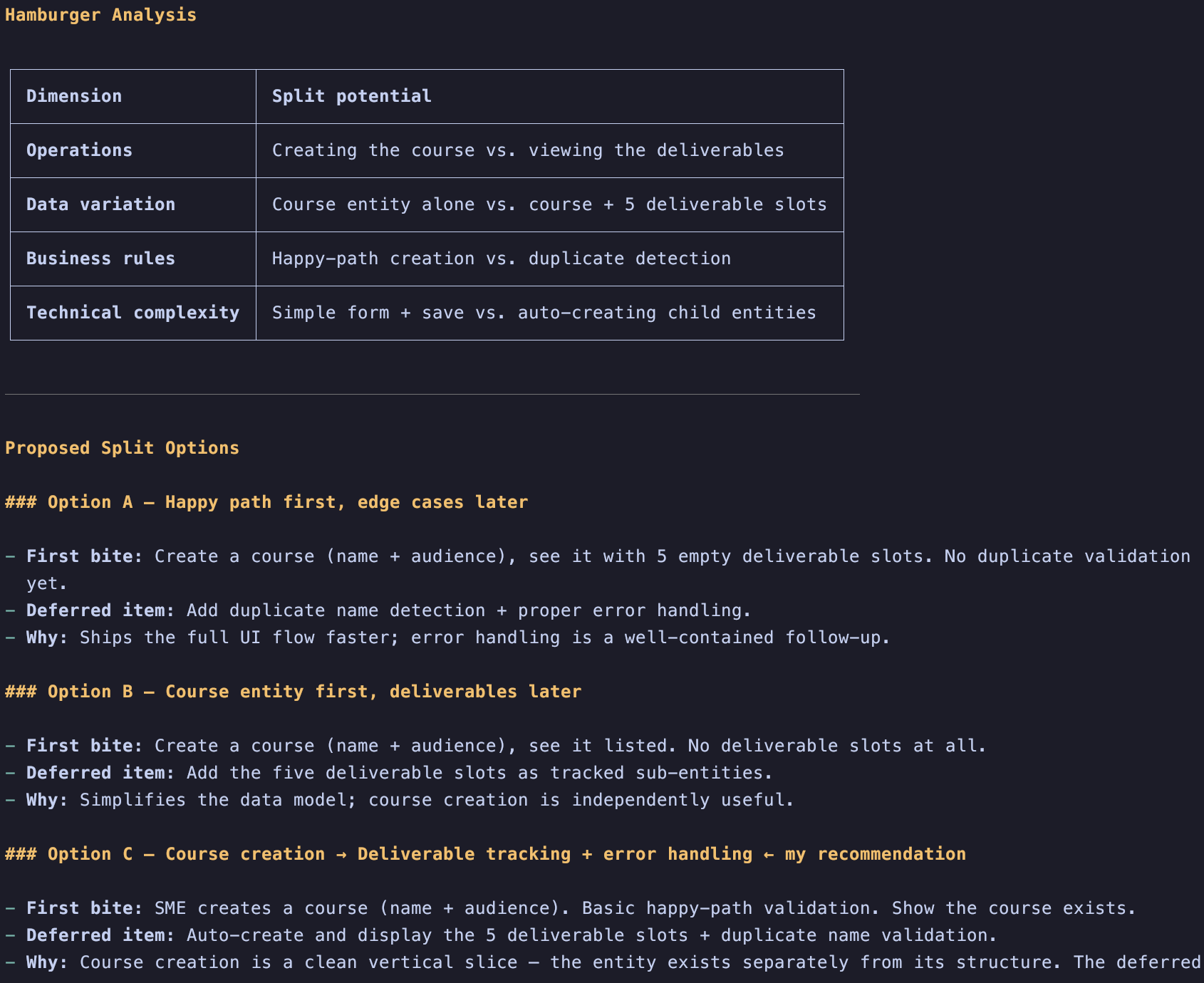
Se un elemento è troppo grande, l’LLM può aiutarti a dividerlo in modi diversi. Una volta diviso, l’LLM si concentrerà sul raffinare il primo pezzo e genererà un nuovo elemento in fondo al Product Backlog che avrà solo un Card.md. In questo modo puoi concentrarti prima sull’incremento corrente e far evolvere il tuo prodotto più rapidamente.
Fare refinement senza coinvolgere l’utente finale non è refinement, è speculazione. Queste skill possono e devono essere usate per provocare una conversazione tra persone.
Principio 3: Le tracce delle decisioni sono più utili della documentazione dello stato attuale
Ci sono cose che gli LLM sanno fare davvero bene, e dovremmo sfruttarle. Sono piuttosto bravi a leggere un mucchio di testo e sintetizzarlo. Per questo, invece di mantenere un documento aggiornato che descrive lo stato attuale del prodotto, stiamo mantenendo un changelog.
La tool /pbl-timeline mostra in una timeline come il tuo Product Backlog è evoluto nel tempo
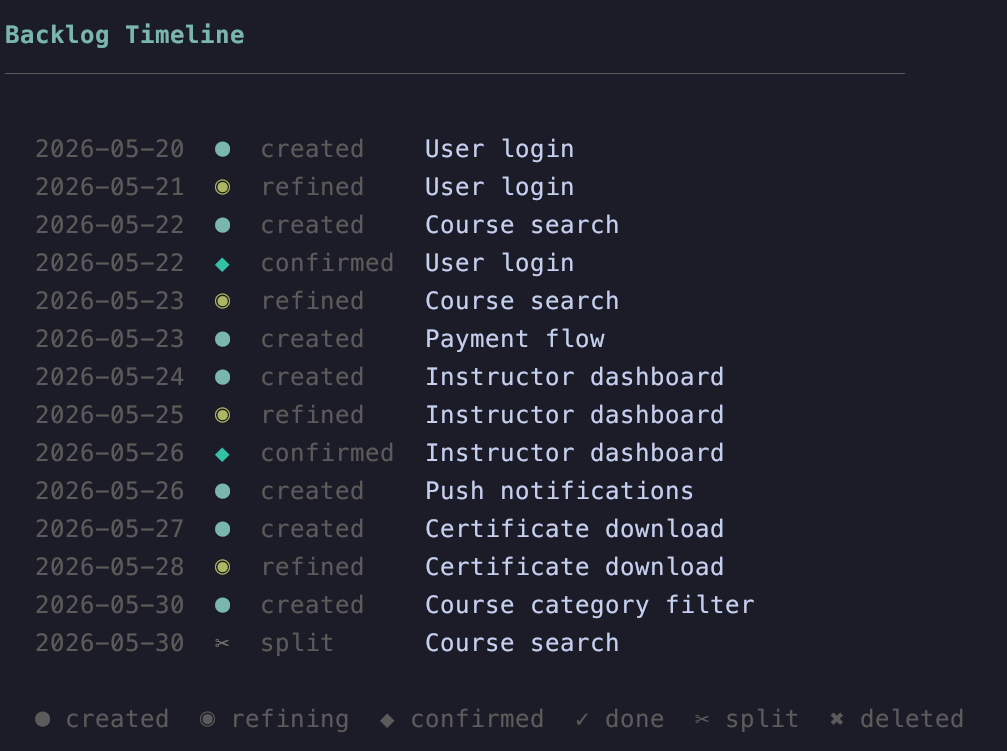
Il pbl-skills crea una directory nascosta chiamata .history per tenere traccia di tutto ciò che è accaduto. Ancora una volta: la cronologia fa parte della tua codebase. Se chiedi all’LLM di eliminare un elemento o lo elimini tramite l’interfaccia di Pi, è una soft delete. L’elemento verrà spostato in una directory nascosta e farà ancora parte del tuo repository. Lo stesso vale per gli elementi completati.
La documentazione persistente è meno rilevante quando puoi ottenere informazioni al volo.
Podcast di Thoughtworks con Birgitta Böckeler e Laura Tacho (ascoltalo!)
Principio 4: Il lavoro svolto degrada le informazioni più rapidamente del tempo trascorso
Se sei mai stato a uno dei miei corsi, probabilmente mi hai sentito dire che in un ambiente complesso le informazioni invecchiano come il latte. È ancora così, ma ora dobbiamo classificare questa obsolescenza in due categorie:
Obsolescenza Esogena - Età dell’Informazione
Diciamo che raffini un elemento e aggiungi molte informazioni oggi, ma non lo implementi. La settimana successiva succede qualcosa di imprevisto e tutte quelle informazioni invecchiano molto rapidamente. Devi raffinarlo di nuovo.
(C’è anche un post interessante che ho scritto tempo fa: Information expires and specificity adds to its obsolescence)
Obsolescenza Endogena - Increment Drift
Immagina di avere un Product Backlog con 10 elementi e di raffinare l’elemento numero 8. Il tuo team sta usando un LLM per aiutare a programmare, quindi nello stesso giorno riesce a implementare i primi 7 elementi e chiude la giornata. La mattina dopo arrivi all’elemento #8. Se pensiamo all’età dell’informazione, non sembra un problema, vero? L’hai raffinato ieri!
Ma… la tua codebase è cambiata molto! Hai implementato 7 nuovi elementi nel frattempo. Sono state prese decisioni architetturali, forse le interfacce sono cambiate, e anche i bisogni.
Questo è quello che chiamo Increment Drift: più incrementiamo un prodotto, maggiore è la probabilità che le informazioni che avevamo memorizzato nel Product Backlog siano diventate obsolete. Man mano che acceleriamo sempre di più lo sviluppo software, la mia teoria è che questa metrica tende a diventare più rilevante dell’Età dell’Informazione per la maggior parte dei prodotti.
Sto scommettendo che l’Increment Drift diventerà più rilevante semplicemente perché la nostra percezione della correlazione tra tempo e lavoro svolto non sta solo cambiando rapidamente, ma sta diventando incredibilmente volatile. E scommetto che renderà alcune metriche basate sul tempo meno informative, specialmente nei micro-contesti.
Sono affascinato da questo concetto e non sarà l’ultima volta che ne parlo.
La skill
/pbl-diagnosevaluta entrambe le metriche e ti avvisa se trova anti-pattern comuni nel tuo Product Backlog.
Quando esegui /pbl-diagnose, l’LLM ti avviserà se hai troppi elementi raffinati, se hai completato troppi elementi dopo aver raffinato un altro elemento (Increment Drift), valuterà l’età dell’informazione e verificherà persino se l’evoluzione della tua Definizione di Done è coerente con la quantità di cambiamenti architetturali che hai fatto.
Il plugin pbl-skills ha un comando (esclusivo di pi-dev) chiamato pbl-metrics che è deterministico (nessun LLM coinvolto) e mostra semplicemente queste metriche sullo schermo, mentre la skill /pbl-diagnose può essere usata per alimentare queste metriche in modo che l’LLM possa avvisarti se qualcosa sembra strano.
Altri comandi e skill
/pbl-implement: Avvia l’implementazione del primo elemento raffinato nel Product Backlog. Scriverà i test in base al fileConfirmation.mdcorrispondente/pbl-done: Verifica la Definizione di Done e segna l’elemento come completato/pbl-add: Aggiunge un nuovo elemento al Product Backlog. L’LLM farà domande semplici per creare solo il fileCard.md
Qual è il modo migliore per provarlo?
Il modo migliore per provarlo (gratuitamente!) è:
- Installare pi.dev
- Creare un account su OpenCode
- Ottenere la tua chiave API di OpenCode e aggiungerla a Pi usando
/login - Scegliere un modello gratuito come BigPickle e divertirsi
Cosa viene dopo?
Il mio buon amico Donato mi ha grigliato (riferimento a grill-me, una skill creata da Matt Pocock) sulla tool e ho dei compiti da fare:
- Come funziona con i progetti brownfield?
- Qual è il modo migliore per gestirla con gli agenti autonomi?
Il mio istinto in questo momento è che funzionerebbe per i progetti brownfield con un tasso di beneficio crescente: più la usi, meglio funziona. Dopotutto, i product backlog sono organismi viventi. E man mano che il nostro changelog cresce, crescono anche le informazioni disponibili per l’LLM con cui lavorare.
Per ora, gli agenti autonomi non sono il focus del plugin.
Ma forse darò un /pbl-add a questo. :)
{kind=link}