

Seu backlog não está desatualizado porque o tempo passou. Está desatualizado porque você entregou.
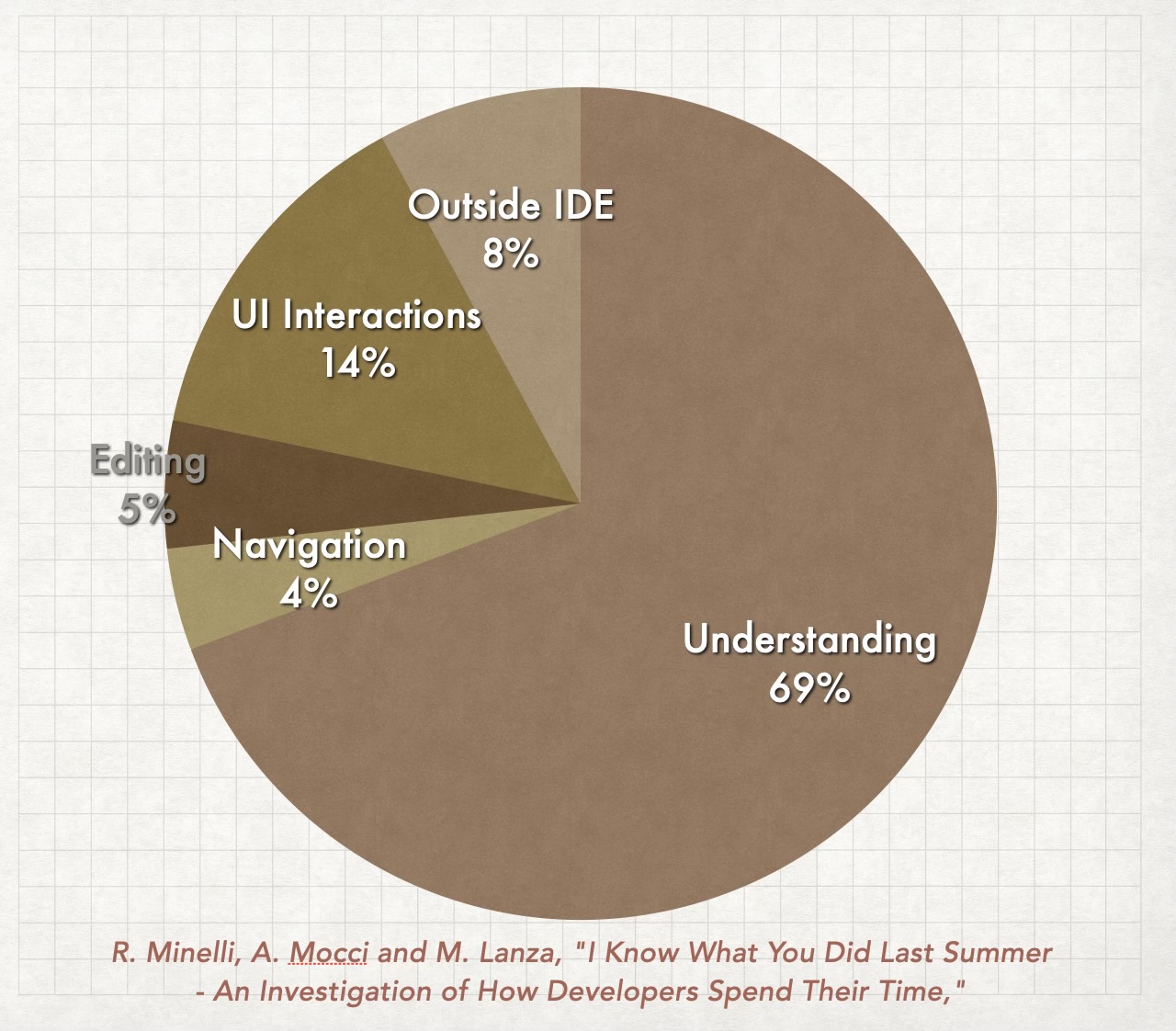
Esta semana finalmente coloquei em palavras uma conclusão que vinha se formando há meses na minha cabeça confusa: o desenvolvimento assistido por LLM provavelmente quebrou uma das nossas métricas mais confiáveis: a Idade da Informação (que aliás é uma das minhas métricas favoritas). Costumávamos medir a obsolescência da informação em tempo, do tipo: “aquele item foi refinado há três semanas, provavelmente está desatualizado.” Isso nem sempre funciona mais. Uma especificação pode se tornar obsoleta em um único dia, não porque o mundo mudou, mas porque o time entregou sete incrementos desde o café da manhã (mais sobre a expiração da informação aqui).
Essa percepção me levou a criar o pbl-skills, um plugin que mantém seu Product Backlog dentro do repositório de código e rastreia uma métrica que estou chamando de Increment Drift no lugar da Idade da Informação.
Veja como funciona:
pbl-skills e seus 4 princípios
O plugin se chama pbl-skills e há duas formas de usá-lo. Se você usa o pi, basta digitar:
pi install -l npm:pbl-skills
Se você estiver usando outro harness (como Claude Code ou Codex), ainda pode se beneficiar das skills. Elas estão disponíveis em:
Repositório pbl-skills no Github
O plugin é baseado em 4 princípios que desenvolvi depois de dois anos experimentando com desenvolvimento aumentado por LLM. Os dois primeiros são escolhas arquiteturais, o terceiro é uma abordagem de documentação, e o quarto é provavelmente a maior descoberta que tive durante esse processo. Então, se você não quiser ler o post inteiro, pule direto para o quarto princípio.
Vamos falar sobre cada um deles e conectar cada princípio a uma funcionalidade implementada no pbl-skills.
Princípio 1: O Product Backlog deve viver no repositório de código
Simples. Se estamos usando LLMs para desenvolver software, toda a informação sobre o projeto deve estar na pasta do projeto. Por isso o plugin tem um comando chamado /pbl-kickoff que pode pegar uma frase curta ou um arquivo .md com a ideia do projeto e transformá-la em um Product Backlog.
O comando
/pbl-kickofffoi inspirado no comandogrill-mecriado por Matt Pocock.
O Product Backlog é criado na pasta ./product-backlog, e cada item ganha uma subpasta dedicada que fica assim:
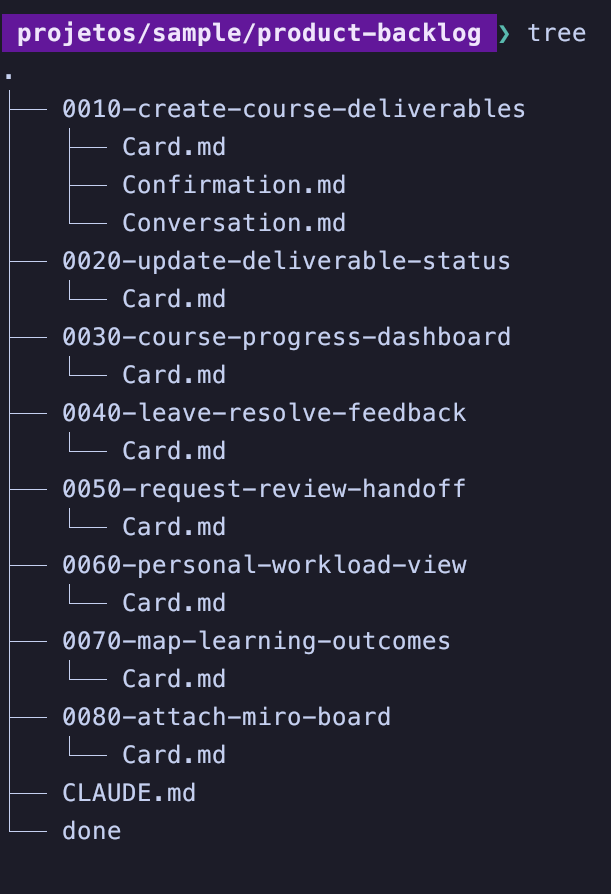
O Product Backlog também é ordenado, e usa números nos nomes das pastas para isso. Simples, mas funciona. Além disso, os itens são sempre fatias verticais do produto.
Nesse ponto, o LLM também vai propor uma Definição de Pronto inicial para você. Não precisa ser muito criterioso aqui, porque a intenção é criar um padrão de qualidade que vai evoluir com o tempo.
Este é um plugin bastante opinado: os itens sempre usarão os 3 C’s das User Stories e o formato Connextra, e isso nos ajudará a rastrear o estado do Product Backlog.
Itens com apenas um arquivo Card.md na pasta são considerados Brutos.
Itens com Card.md e Conversation.md na pasta são itens que ainda estamos Refinando.
Itens com Card.md, Conversation.md e Confirmation.md na pasta são considerados Prontos.
Princípio 2: Um item do backlog deve ser compreensível de forma independente por um agente sem contexto prévio
Não quero que meu contexto cresça indefinidamente. Quero entrar e começar a refinar um item. E é isso que acontece quando você executa /pbl-refine: o LLM vai pegar o item mais prioritário do seu Product Backlog e te entrevistar sobre ele até estar satisfeito com as informações.
O comando
/pbl-refinefoi inspirado no comandogrill-with-docscriado por Matt Pocock.
Se você não tiver informações suficientes ou parar a conversa no meio, o LLM criará um resumo da conversa em um arquivo Conversation.md. Se você responder todas as perguntas, o LLM vai propor um arquivo Confirmation.md para você. Aqui, e em qualquer ponto desse processo, você pode discordar e adicionar algo que o LLM perdeu.
O arquivo Confirmation.md é estruturado para ser uma confirmação idealmente executável, facilmente transcrita para frameworks de teste como RSpec, Jest, JUnit, ExUnit, etc.
Há também outra skill que pode ser invocada manualmente ou sugerida pelo LLM: /pbl-split.
O comando /pbl-split foi inspirado no método hamburger criado por Gojko Adzic
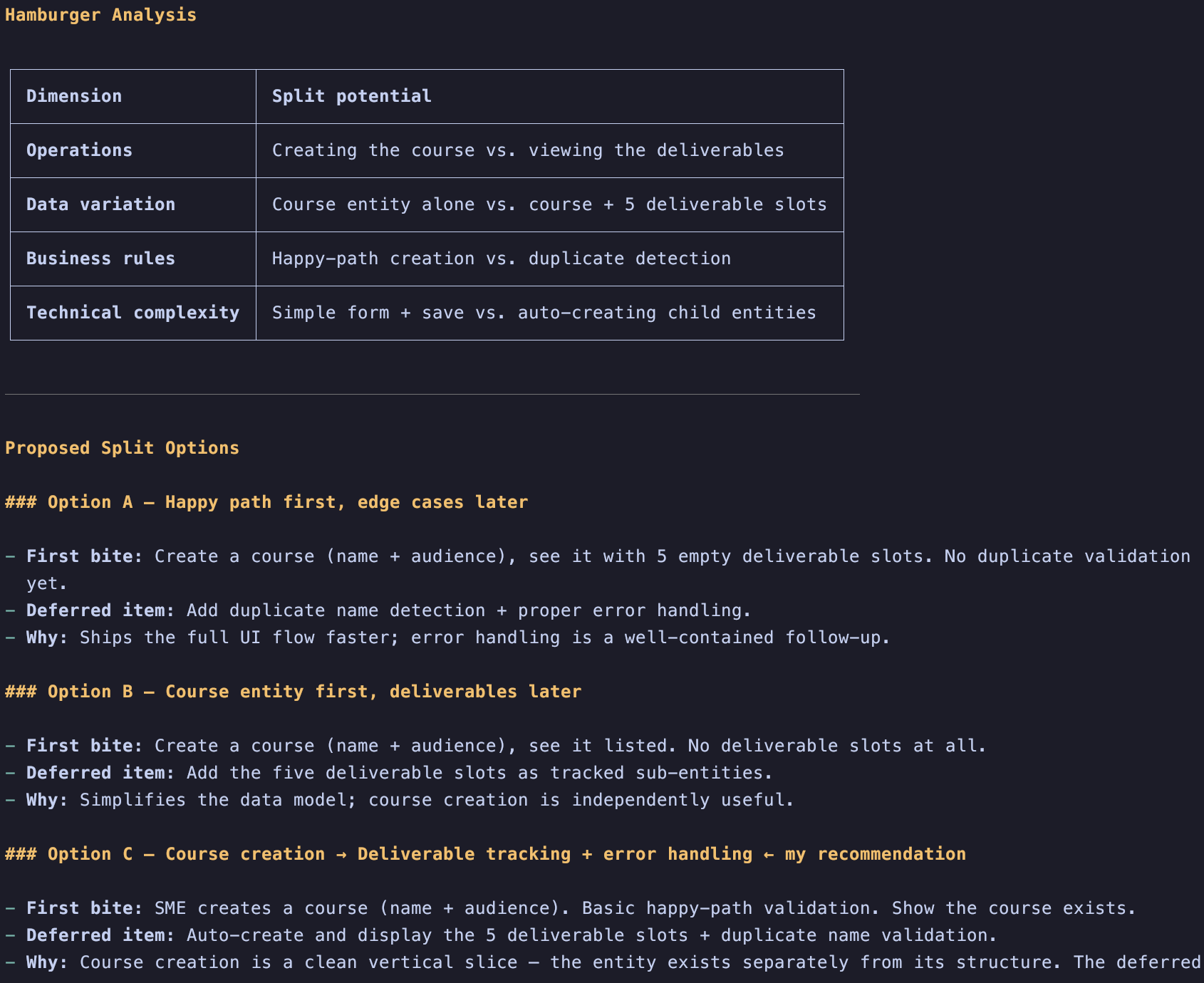
Se um item é muito grande, o LLM pode ajudar a dividi-lo de diferentes formas. Uma vez dividido, o LLM vai focar em refinar a primeira parte e gerar um novo item no final do Product Backlog que terá apenas um Card.md. Assim você pode se concentrar no incremento atual primeiro e evoluir seu produto mais rápido.
Fazer refinamento sem envolver o usuário final não é refinamento, é especulação. Essas skills podem e devem ser usadas para provocar uma conversa entre pessoas.
Princípio 3: Trilhas de decisão são mais úteis do que documentação do estado atual
Há coisas que os LLMs fazem muito bem, e devemos aproveitar isso. Eles são bastante bons em ler um monte de texto e resumir coisas. Por isso, em vez de manter um documento atualizado descrevendo o estado atual do produto, estamos mantendo um changelog.
A tool /pbl-timeline mostra em uma linha do tempo como seu Product Backlog evoluiu ao longo do tempo
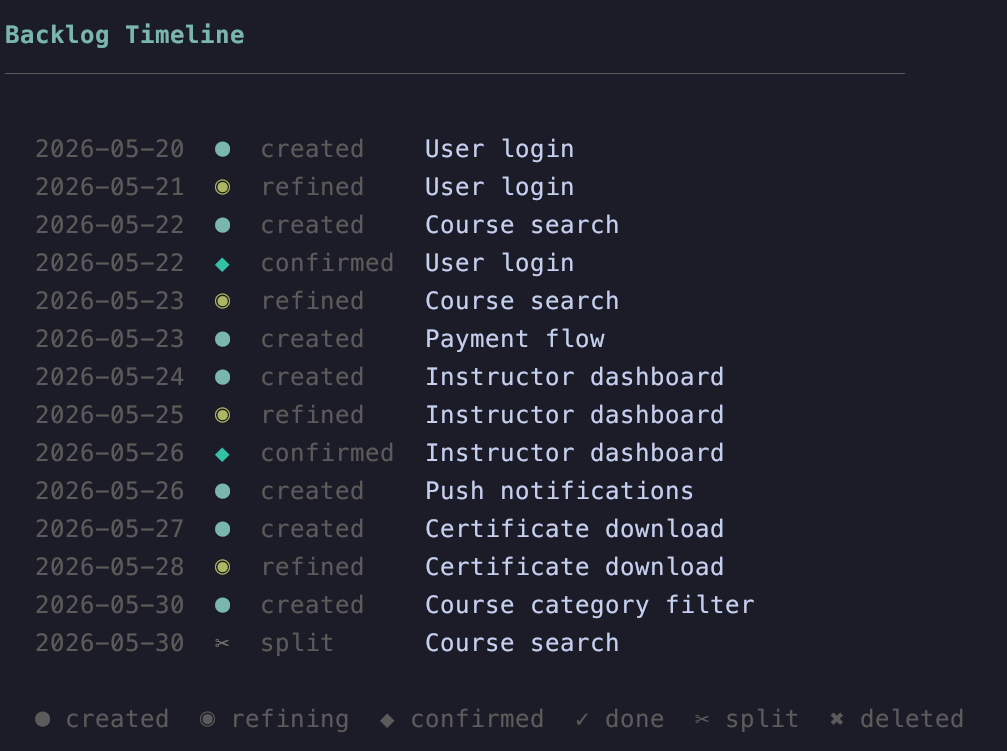
O pbl-skills cria um diretório oculto chamado .history para rastrear tudo que aconteceu. De novo: o histórico é parte do seu repositório. Se você pedir ao LLM para deletar um item ou deletá-lo pela interface do Pi, é uma deleção suave. O item será enviado para um diretório oculto e ainda fará parte do seu repositório. O mesmo vale para itens concluídos.
Documentação persistente é menos relevante quando você pode obter informações sob demanda.
Podcast da Thoughtworks com Birgitta Böckeler e Laura Tacho (ouça!)
Princípio 4: O trabalho realizado degrada a informação mais rápido do que o tempo decorrido
Se você já foi a uma das minhas aulas, provavelmente me ouviu dizer que em ambientes complexos a informação envelhece como leite. Ainda acontece, mas agora precisamos classificar essa obsolescência em duas categorias:
Obsolescência Exógena - Idade da Informação
Digamos que você refine um item e adicione um monte de informações hoje, mas não o implemente. Na semana seguinte, algo louco acontece e toda aquela informação envelhece muito mal. Você precisa refiná-lo novamente.
(Tem um post interessante que escrevi sobre isso há algum tempo: A relação entre especificidade e obsolescência)
Obsolescência Endógena - Increment Drift
Imagine que você tem um Product Backlog com 10 itens e refina o item número 8. Seu time está usando um LLM para ajudar a programar, então no mesmo dia vocês conseguem implementar os primeiros 7 itens e encerram o dia. Na manhã seguinte você chega ao item #8. Se pensarmos em idade da informação, não parece um problema, certo? Você refinou ontem!
Mas… seu código mudou muito! Você implementou 7 novos itens durante esse tempo. Decisões arquiteturais foram tomadas, talvez interfaces tenham mudado, e necessidades também.
Isso é o que chamo de Increment Drift: quanto mais incrementamos um produto, maior é a probabilidade de que a informação armazenada no Product Backlog tenha envelhecido. Conforme aceleramos o desenvolvimento de software cada vez mais, minha teoria é que essa métrica tende a se tornar mais relevante do que a Idade da Informação para a maioria dos produtos.
Estou apostando que o Increment Drift vai se tornar mais relevante simplesmente porque nossa percepção sobre a correlação entre tempo e trabalho realizado não está apenas mudando rapidamente: está se tornando incrivelmente volátil. E aposto que isso vai tornar algumas métricas baseadas em tempo menos informativas, especialmente em micro-contextos.
Estou fascinado com esse conceito e não será a última vez que falo sobre isso.
A skill
/pbl-diagnoseavalia ambas as métricas e te alerta se encontrar anti-padrões comuns no seu Product Backlog.
Quando você executa /pbl-diagnose, o LLM vai te alertar se você tem muitos itens refinados, se terminou muitos itens depois de refinar outro item (Increment Drift), vai avaliar a idade da informação e até verificar se a evolução da sua Definição de Pronto é coerente com a quantidade de mudanças arquiteturais que você fez.
O plugin pbl-skills tem um comando (exclusivo do pi-dev) chamado pbl-metrics que é determinístico (sem LLM envolvido) e apenas mostra essas métricas na tela, e a skill /pbl-diagnose pode ser usada para alimentar essas métricas para que o LLM possa te avisar se algo estiver estranho.
Outros comandos e skills
/pbl-implement: Inicia a implementação do primeiro item refinado no Product Backlog. Vai escrever testes de acordo com o arquivoConfirmation.mdcorrespondente/pbl-done: Verifica a Definição de Pronto e marca o item como concluído/pbl-add: Adiciona um novo item ao Product Backlog. O LLM vai fazer perguntas simples para criar apenas o arquivoCard.md
Qual é a melhor forma de experimentar?
A melhor forma de experimentar (de graça!) é:
- Instalar o pi.dev
- Criar uma conta no OpenCode
- Obter sua chave de API do OpenCode e adicioná-la ao Pi usando
/login - Escolher um modelo gratuito como o BigPickle e se divertir
O que vem por aí?
Bem, meu bom amigo Donato me grelhou (referência ao grill-me, uma skill criada por Matt Pocock) sobre a ferramenta e tenho alguns deveres de casa:
- Como trabalhar com ela em projetos legados?
- Qual a melhor forma de entregá-la a agentes autônomos?
Meu instinto agora é que funcionaria para projetos legados com uma taxa de benefício crescente: quanto mais você usa, melhor fica. Afinal, product backlogs são organismos vivos. E conforme nosso changelog cresce, crescem também as informações disponíveis para o LLM trabalhar.
Por enquanto, agentes autônomos não são o foco do plugin.
Mas talvez eu dê um /pbl-add nisso. :)
{kind=link}